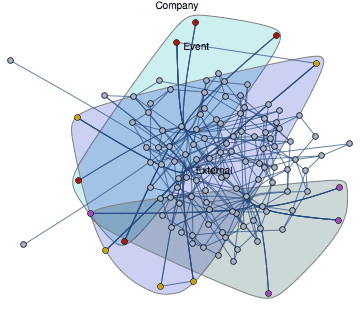
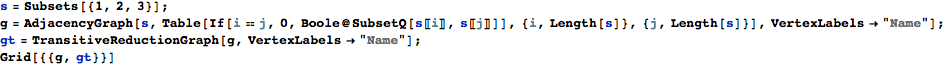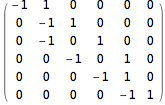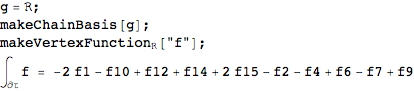In the past twenty years we have served and helped customers in many ways, all centered around graphs and how to enable a particular business vision with the help of graphs. There is usually the need for graph visualization and reporting in some way and this leads to the development of (custom) dashboard-like solutions. The challenge is always the fact that when it comes to reporting all solutions (say, PowerBI, Tableau and alike) are for relational data and not graph databases. For good reasons, the tabular format is easier to ‘linearize’ into a pie chart or a data grid.
In the same way, whenever you have graphs there is the need to edit them, the standard CRUD (create, read, update, delete) challenge. Here as well, there are tons of solutions for SQL backends but few for graphs. The OGMs (object graph models) are usually for Neo4j.
The re-creation of the same thing over and over again (as a consultant delivering bespoke solutions) is related to the fact that the intellectual property has to be unique and that in principle one can reuse some bits of code, in theory it never is that easy. Frameworks change, different backend flavors, different technologies. The technology landscape is every day a new challenge.
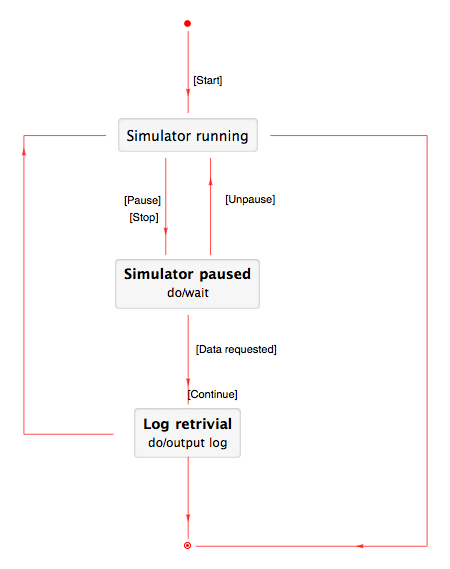
So, despite all constraints and challenges we set out to develop something best described as a stepping stone for graph-driven applications. The result is called Qwiery and is a set of open source tools to develop apps on top of graph stores.
Qwiery contains things like:
a flexible data access layer
a set of components to develop dashboards, terminals, notebook interfaces
wrappers around our favorite graph visualization frameworks (yFiles, Ogma, Cytoscape…)
utilities (working with datetime, strings, durations, colors…)
entities and messages
graphs (trees, graphs, random graphs, traversals…)
and much more. Each of these elements deserve a blog post on its own and the extensible data access layer is, in particular, a world on its own.
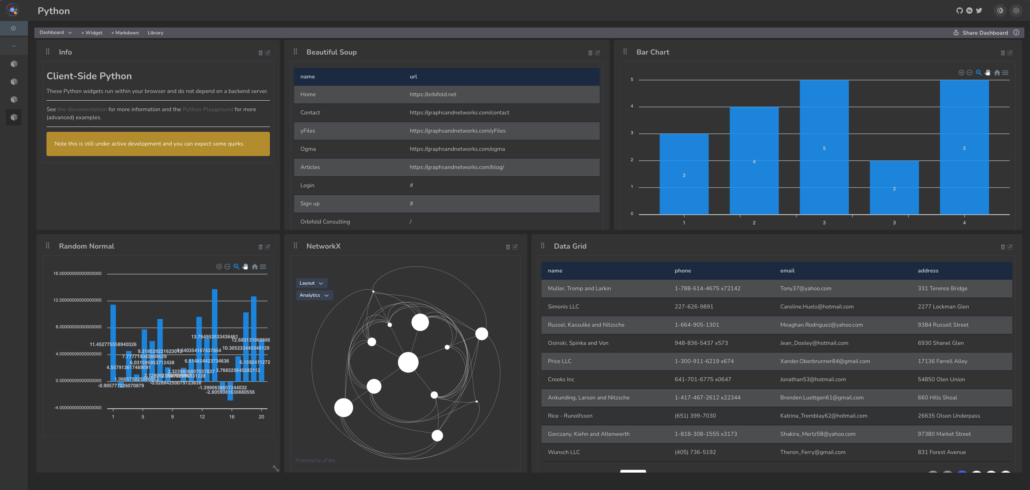
As show-cases we developed two full-fledge apps using Qwiery: Qwiery Dashboards and Qwiery Editor.
Qwiery Dashboards is a dashboarding app for graphs. It comes with:
widgets specifically designed to query Cypher (property graph) databases like Neo4j and MemGraph
client-side Python integration (enabling NetworkX, scikit-learn, pandas and numpy within the dashboards)
In addition, we have backend services (in Python, NodeJs and .Net) allowing to go beyond the open source offering and giving a lot more juice. Please contact us for more information.
The code in this article can be found in this Colab notebook .
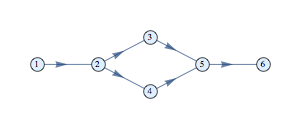
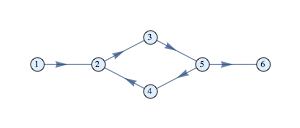
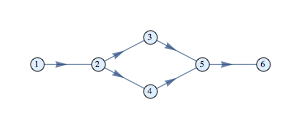
NetworkX is a graph analysis library for Python. It has become the standard library for anything graphs in Python. In addition, it’s the basis for most libraries dealing with graph machine learning. Stellargraph, in particular, requires an understanding of NetworkX to construct graphs. Below is an overview of the most important API methods. The official documentation is extensive but it remains often confusing to make things happen. Some simple questions (adding arrows, attaching data…) are usually answered in StackOverflow, so the guide below collects these simple but important questions.
General remarks
The library is flexible but these are my golden rules:
do not use objects to define nodes, rather use integers and set data on the node. The layout has issues with objects.
the API changed a lot over the versions, make sure when you find an answer somewhere that it matches your version. Often methods and answers do not apply because they relate to an older version.
if you wish to experiment with NetworkX in Jupyter, go for Colab and use this stepping stone:
!pip install faker
import networkx as nx
import matplotlib.pyplot as plt
from faker import Faker
faker = Faker()
%matplotlib inline
Creating graphs
There are various constructors to create graphs, among others:
# default
G = nx.Graph()
# an empty graph
EG = nx.empty_graph(100)
# a directed graph
DG = nx.DiGraph()
# a multi-directed graph
MDG = nx.MultiDiGraph()
# a complete graph
CG = nx.complete_graph(10)
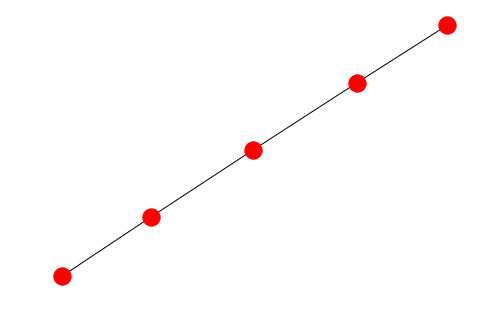
# a path graph
PG = nx.path_graph(5)
# a complete bipartite graph
CBG = nx.complete_bipartite_graph(5,3)
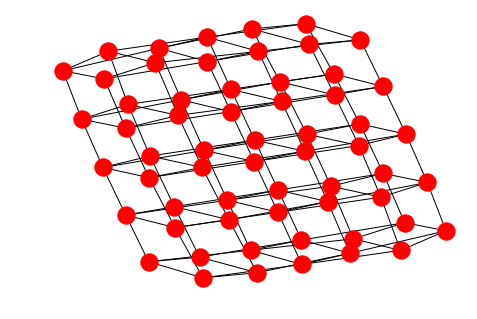
# a grid graph
GG = nx.grid_graph([2, 3, 5, 2])
Make sure you understand each class and the scope of each. Certain algorithms, for instance, work only with undirected graphs.
Graph generators
Graph generators produce random graphs with particular properties which are of interest in the context of statistics of graphs. The best-known phenomenon is six degrees of separation which you can find on the internet, our brains, our social network and whatnot.
Erdos-Renyi
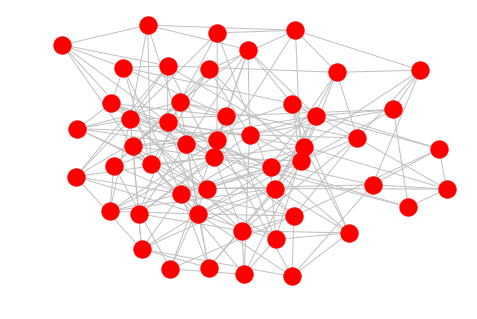
The Erdos-Renyi model is related to percolations and phase transitions but is in general the most generic random graph model. The first parameter is the amount of nodes and the second a probability of being connected to another one.
er = nx.erdos_renyi_graph(50, 0.15)
nx.draw(er, edge_color='silver')
Watts-Strogratz
The Watts-Strogratz model produces small-world properties. The first parameter is the amount of node then follows the default degree and thereafter the probability of rewiring and edge. So, the rewiring probability is like the mutation of an otherwise fixed-degree graph.
The Barabasi-Albert model reproduces random scale-free graphs which are akin to citation networks, the internet and pretty much everywhere in nature.
ba = nx.barabasi_albert_graph(50, 5)
nx.draw(ba)
You can easily extract the exponential distribution of degrees:
g = nx.barabasi_albert_graph(2500, 5)
degrees = list(nx.degree(g))
l = [d[1] for d in degrees]
plt.hist(l)
plt.show()
Drawing graphs
The draw method without additional will present the graph with spring-layout algorithm:
nx.draw(PG)
There are of course tons of settings and features and a good result is really dependent on your graph and what you’re looking for. If we take the bipartite graph for example it would be nice to see the two sets of nodes in different colors:
from networkx.algorithms import bipartite
X, Y = bipartite.sets(CBG)
cols = ["red" if i in X else "blue" for i in CBG.nodes() ]
nx.draw(CBG, with_labels=True, node_color= cols)
The grid graph on the other hand is better drawn with the Kamada-Kawai layout in order to see the grid structure:
nx.draw_kamada_kawai(GG)
Nodes
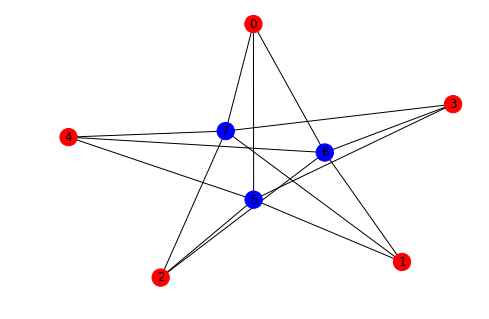
If you start from scratch the easiest way to define a graph is via the add_edges_from method as shown here:
from faker import Faker
faker = Faker()
class Person:
def __init__(self, name):
self.name = name
@staticmethod
def random():
return Person(faker.name())
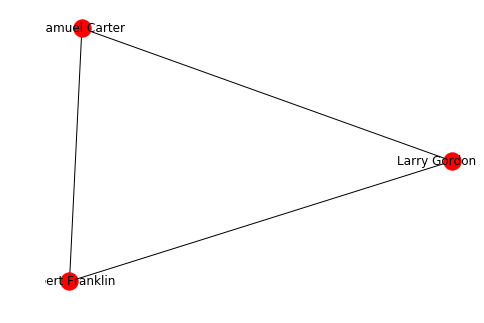
g = nx.Graph()
a = Person.random()
b = Person.random()
c = Person.random()
g.add_edges_from([(a,b), (b,c), (c,a)])
# to show the names you need to pass the labels
nx.draw(g, labels = {n:n.name for n in g.nodes()}, with_labels=True)
As mentioned earlier, it’s better to use numbers for the nodes and set the data via the set_node_attributes methods as shown below.
Edges
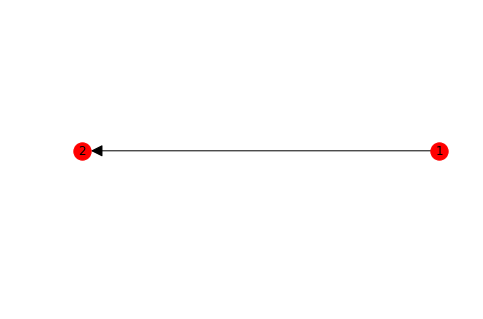
Arrows can only be shown if the graph is directed. NetworkX is essentially a graph analysis library and much less a graph visualization toolbox.
G = nx.DiGraph()
a = Person.random()
b = Person.random()
G.add_node(0, data=a)
G.add_node(1, data=b)
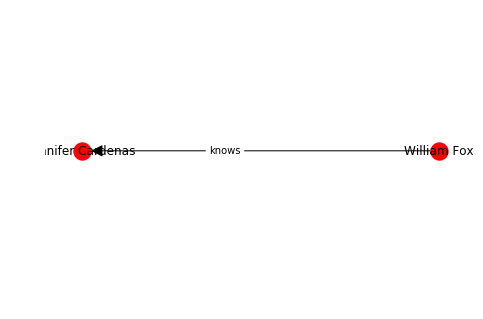
G.add_edge(0, 1, label="knows")
labelDic = {n: G.nodes[n]["data"].name for n in G.nodes()}
edgeDic = {e: G.get_edge_data(*e)["label"] for e in G.edges}
kpos = nx.layout.kamada_kawai_layout(G)
nx.draw(G, kpos, labels=labelDic, with_labels=True, arrowsize=25)
nx.draw_networkx_edge_labels(G, kpos, edge_labels=edgeDic, label_pos=0.4)
Analysis
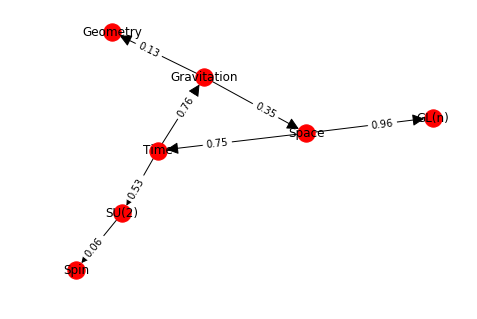
There many analysis oriented methods in NetworkX, below are just a few hints to get you started. Let’s assemble a little network to demonstrate the methods:
import random
gr = nx.DiGraph()
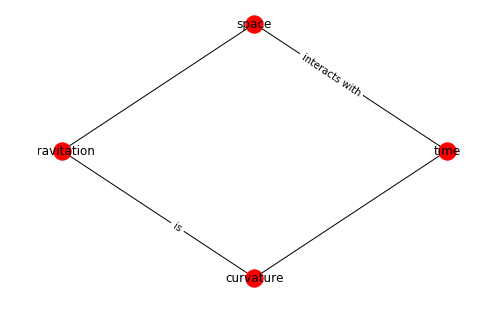
gr.add_node(1, data={'label': 'Space'})
gr.add_node(2, data={'label': 'Time'})
gr.add_node(3, data={'label': 'Gravitation'})
gr.add_node(4, data={'label': 'Geometry'})
gr.add_node(5, data={'label': 'SU(2)'})
gr.add_node(6, data={'label': 'Spin'})
gr.add_node(7, data={'label': 'GL(n)'})
edge_array = [(1, 2), (2, 3), (3, 1), (3, 4), (2, 5), (5, 6), (1, 7)]
gr.add_edges_from(edge_array)
for e in edge_array:
nx.set_edge_attributes(gr, {e: {'data':{'weight': round(random.random(),2)}}})
gr.add_edge(*e, weight=round(random.random(),2))
labelDic = {n:gr.nodes[n]["data"]["label"] for n in gr.nodes()}
edgeDic = {e:gr.edges[e]["weight"] for e in G.edges}
kpos = nx.layout.kamada_kawai_layout(gr)
nx.draw(gr,kpos, labels = labelDic, with_labels=True, arrowsize=25)
o=nx.draw_networkx_edge_labels(gr, kpos, edge_labels= edgeDic, label_pos=0.4)
Getting the adjacency matrix gives a sparse matrix. You need to use the todense method to see the dense matrix. There is also a to_numpy_matrix method which makes it easy to integrate with numpy mechanics:
If you need to use the edge data in the adjacency matrix this goes via the attr_matrix:
nx.attr_matrix(gr, edge_attr="weight")
Simple things like degrees are simple to access:
list(gr.degree)
The shortest path between two vertices is just as simple but please note that there are dozens of variations in the library:
nx.shortest_path(gr, 1, 6, weight="weight")
Things like the radius of a graph or the cores is defined for undirected graphs:
nx.radius(gr.to_undirected())
nx.find_cores(gr)
Centrality is also a whole world on its own. If you wish to visualize the betweenness centrality you can use something like:
cent = nx.centrality.betweenness_centrality(gr)
nx.draw(gr, node_size=[v * 1500 for v in cent.values()], edge_color='silver')
Getting the connected components of a graph:
nx.is_connected(gr.to_undirected())
comps = nx.components.connected_components(gr.to_undirected())
for c in comps:
print(c)
Clique
A clique is a complete subgraph of a particular size. Large, dense subgraphs are useful for example in the analysis of protein-protein interaction graphs, specifically in the prediction of protein complexes.
def show_clique(graph, k = 4):
'''
Draws the first clique of the specified size.
'''
cliques = list(nx.algorithms.find_cliques(graph))
kclique = [clq for clq in cliques if len(clq) == k]
if len(kclique)>0:
print(kclique[0])
cols = ["red" if i in kclique[0] else "white" for i in graph.nodes() ]
nx.draw(graph, with_labels=True, node_color= cols, edge_color="silver")
return nx.subgraph(graph, kclique[0])
else:
print("No clique of size %s."%k)
return nx.Graph()
Taking the Barabasi graph above and checking for isomorphism with the complete graph of the same size we can check that the found result is indeed a clique of the requested size.
red = nx.random_lobster(100, 0.9, 0.9) nx.draw(ba)
petersen = nx.petersen_graph()
nx.draw(petersen)
G=nx.karate_club_graph()
cent = nx.centrality.betweenness_centrality(G)
nx.draw(G, node_size=[v * 1500 for v in cent.values()], edge_color='silver')
Graph visualization
As described above, if you want pretty images you should use packages outside NetworkX. The dot and GraphML formats are standards and saving a graph to a particular format is really easy. For example, here we save the karate-club to GraphML and used yEd to layout things together with a centrality resizing of the nodes.
In the context of machine learning and real-world data graphs it’s important that nodes and edges carry data. The way it works in NetworkX can be a bit tricky, so let’s make it clear here how it functions.
G = nx.Graph()
G.add_edge(12,15, payload={'label': 'stuff'})
print(G.get_edge_data(12,15))
print(G.get_edge_data(12,15)['payload']['label'])
One can also set the data after the edge is added:
G = nx.Graph()
G.add_edge(12,15)
nx.set_edge_attributes(G, {(12,15): {'payload':{'label': 'stuff'}}})
print(G.get_edge_data(12,15))
print(G.get_edge_data(12,15)['payload']['label'])
Pandas
The library has support for import/export from/to Pandas dataframes. This exchange, however, applies to edges and not to nodes. The row of a frame are used to define an edge and if you want to use a frame for nodes or both, you are on your own. It’s not difficult though, let’s take a graph and turn it into a frame.
g = nx.barabasi_albert_graph(50, 5)
# set a weight on the edges
for e in g.edges:
nx.set_edge_attributes(g, {e: {'weight':faker.random.random()}})
for n in g.nodes:
nx.set_node_attributes(g, {n: {"feature": {"firstName": faker.first_name(), "lastName": faker.last_name()}}})
You can now use the to_pandas_edgeList method but this will only output the weights besides the edge definitions:
import pandas as pd
import copy
node_dic = {id:g.nodes[id]["feature"] for id in g.nodes} # easy acces to the nodes
rows = [] # the array we'll give to Pandas
for e in g.edges:
row = copy.copy(node_dic[e[0]])
row["sourceId"] = e[0]
row["targetId"] = e[1]
row["weight"] = g.edges[e]["weight"]
rows.append(row)
df = pd.DataFrame(rows)
df
FIRSTNAME
LASTNAME
SOURCEID
TARGETID
WEIGHT
0
Rebecca
Griffin
0
5
0.021629
1
Rebecca
Griffin
0
6
0.294875
2
Rebecca
Griffin
0
7
0.967585
3
Rebecca
Griffin
0
8
0.553814
4
Rebecca
Griffin
0
9
0.531532
…
…
…
…
…
…
220
Tyler
Morris
40
43
0.313282
221
Mary
Bolton
41
42
0.930995
222
Colton
Hernandez
42
48
0.380596
223
Michael
Moreno
43
46
0.236164
224
Mary
Morris
45
47
0.213095
Note that you need this denormalization of the node data because you actually need two datasets to describe a graph in a normalized fashion.
StellarGraph
The StellarGraph library can import directly from NetworkX and Pandas via the static StellarGraph.from_networkx method. One important thing to note here is that the features on a node as defined above will not work because the framework expects numbers and not strings or dictionaries. If you do take care of this (one-hot encoding and all that) then this following will do:
If NetworkX does not contain what you are looking for or if you need more performance, the iGraph packageis a good alternative and has bindings for C, R and Mathematica while NetworkX is only working with Python. Another very fast package is the Graph-Tool framework with heaps of features.
Beyond these standalone packages there are also plenty of frameworks integrating with various databases and, of course, the Apache universe. Each graph database has its own graph analytics stack and you should spend some time investigating this space especially because it scales beyond what the standalone packages can.
Finally, graph analytics can also go into terabytes via out-of-memory algorithms, Apache Spark and GPU processing to name a few. The RapidsAI framework is a great solutions with the cuGraph API running on GPU and is largely compatible with the NetworkX API.
https://graphsandnetworks.com/wp-content/uploads/2022/11/NetworkXLogo-1.png280280Orbifold/wp-content/uploads/2021/04/OrbifoldLogo-300x78.pngOrbifold2022-11-21 13:21:462022-11-22 08:51:29NetworkX: an overview
This is an overview of the many ways in which one can create graphs in Mathematica. It demonstrates the ubiquity of graphs and how Mathematica makes it easy to experiment with ideas. At the same time, various Mathematica symbols and techniques are presented which we will cover more in depth in later article.
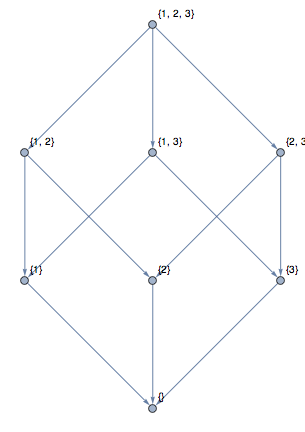
Polyhedral surfaces have been around since antiquity although it wasn’t recognized until Euler that they are in fact closely related to graphs. Take for example the snub-cube
and unwrap its faces
The number of vertices can be found in two ways here, either using the VertexCount property of the PolyHedronData or through the VertexCount property of Graph. The results do not agree though
because the vertex count of the polyhedron is based on its 3D wrapping while the unwrapped graph duplicates some vertices.
Polyhedrons can be combined to give beautiful graphics
The vertices in this case are contained in two graphs, we can use the GraphUnion command to combine them and thus create a new graph. The letter g will be used in this text to denote a graph.
Turning this graph into a polyhedron is not possible (in a straightforward manner)but we can turn it into a 3d graph, which reveals that it’s almost a tree.
How far away from a tree? That’s something we can answer by looking at spanning trees. Although a spanning tree is not unique it still gives a good indication of how many edges (shortcuts) break the tree-like structure
A more numerical value can be obtained from the GraphDifference;
Once you have a graph there are many ways in which it can be turned into another graph. For example, a line graph of a given graph turns edges into vertices and vice versa;
Being a transformation, one can wonder whether there are graphs which remain invariant under this type of transformation. It’s rather easy to create a simple case, the triangle graph is indeed topologically invariant
and this is true for any cycle graph. Assuming that the symmetry of this graph is the key to invariance is misleading though
and similarly with k-ary trees
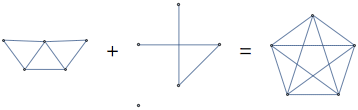
Another way to transform a graph into another one is by asking what it takes to turn the given graph into a complete one. Say, we take a random graph of 5 vertices and 7 edges
and take the graph complement
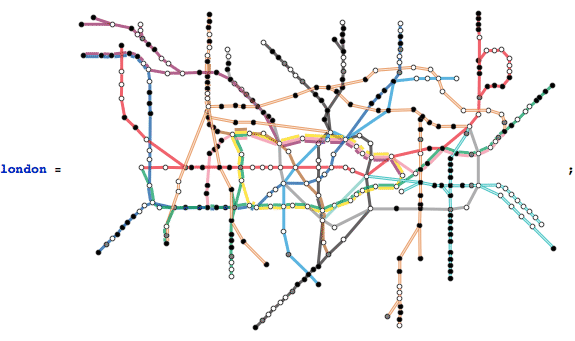
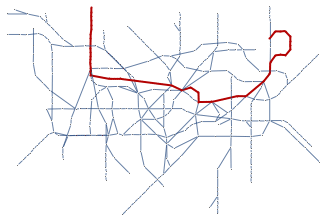
Graphs can be found everywhere in everyday life although it’s not always perceived as such. Millions of people traverse the London tube every day without realizing they do;
What is the longest trajectory across the London underground? One way to answer this question is by looking at the distance matrix
This gives a qualitative result and highlights a few regions with long distances. To find a qualitative answer we take the maximum
This corresponds to the so-called graph diameter, defined as the largest distance across the graph (using geodesic paths);
Of course, we want to know to which couple of stations this distance corresponds
which is a unique solution but can, of course, be traversed in two ways
So, let’s take the first one and see what the (shortest) path is connecting them
The explicit route is hence
To represent this in the graph we first simplify the London graph somewhat.
and then highlight the longest path
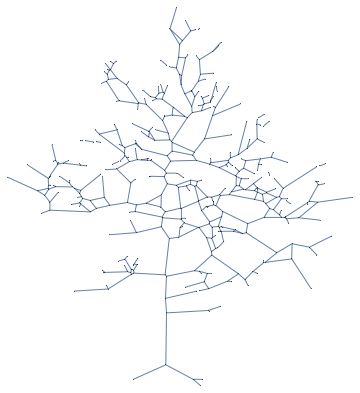
Graphs can be obtained from images through mathematical morphology. The following picture of a tree, for instance, can be turned into a tree-ish graph
This indeed looks very much like a tree, but looks can be misleading;
We can turn this into a genuine tree as follows
It’s actually not a tree but rather a forest, i.e. a collection of trees. This can be seen in various ways. If we apply a tree layout to the graph
we see that there are multiple components. This can be seen by using the ConnectedComponents and the ConnectedGraphQ methods as well
Is connected: False
The world of chemistry also offersa rich collection of graphs. For example, digitonin is a detergent
This molecular structure can be converted to a graph by fetching the edge collection
Mathematica has a rich collection of curated graphs and a fun way to explore a random sample is by means of
There are plenty of categorizations which one can focus on
The polyhedral graphs can be sampled in a similar way
Markov processes can be modelled in Mathematica and their graph representation help understand visually the transitions
This graphical representation does not show the graph as a weighted graph however, but this can be easily done
There are endless ways to manipulate and customize graphs in Mathematica. Here is an example of a hidden feature, the so-called edge bundling which bundles edges in order to achieve greater clarity.
There are plenty of graph types in the software industry which are not directly available but which can be obtained with a bit of effort. Below is an example of a standard flowchart with the essential ingredient being the EdgeShapeFunction which we’ll discuss later on as well.
This results in a more traditional type of graph representation. While pretty much anything and everything is possible one should note though that Mathematica is more geared towards graph computations rather than graph representations.
Mathematica is ideal for rapid prototyping of ideas and combining the multitude of functions. Here is an example of rectangular edges across different types of graph layouts
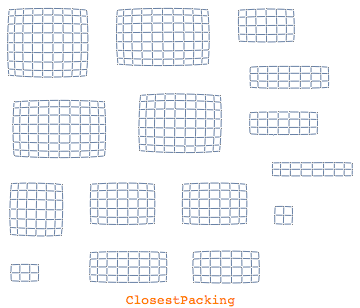
Graph layout is a world on its own and is closely related to graph analysis. Mathematica will by default automatically pick out the most appropriate layout for a given graph as well as the so-called graph packing. Graph packings are about how components of a graph are organized on top of the individual layout. Here is an overview of the possible component arrangements
You can define your own layout of course and specify explicit coordinates. For example, here is an explicit grid layout
Elements of graphs can be highlighted as we showed above with London underground. Vertices belonging in some way together can also be visualized by means of the CommunityGraphPlot which in a way is a combination of graphs and sets.
Yet another way to look at graphs is by considering the edges as segments of polygons.
Conversely, converting a checkered polygon to a graph is possible as well. Taking one of the polygons above we can convert it to a graphics of arrows
and take the coordinates which we then apply to a cycle graph;
Floorplans and maze-like environment are really graphs and it’s easy to generate random mazes like so
Mathematica contains a rich collection of so-called parametric graphs which have diverse types of regularities.
Besides all sorts of graphs with explicit names and the parametric graphs (like k-ary tree) there is a whole arsenal of ways to generate random graphs. There are many reasons why one would want to produce random graphs and it’s in fact an acadmic branch on its own. Among other: – experiment with existing or invent new graph layout algorithms (graph embeddings) – research collective behaviors or properties of graphs with certain constraints (statistical physics based on graphs) – model epidemic and viral algorithms – test out graph theoretic concepts (centrality and other measures)
Here is a sample of random graphs based on various distributions:
Sparse arrays are an important ingredient in graph drawing, most matrices deduced from a graph are sparse. Conversely, you can create graphs from sparse arrays. For example, the following ladder diagram is based on a banded sparse array
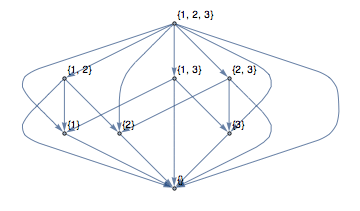
An interesting way to construct graphs is by looking at relationships between sets of objects. For example, the inclusion or subset operation gives a partially ordered set which can be made even more clear by looking at the so-called transitive reduction of the graph. The transitive reduction removes edges which can be deduced from the transitive closure.
Finally, sound can also be converted to a graph by looking at the line graph outputted by default when loading a wave;
It produces beautiful floral patterns and is a good representation of the complexity of the data. For a comparison, here is the graph corresponding to the alt-sax
https://graphsandnetworks.com/wp-content/uploads/2021/07/CreatingGraphs_9.gif191191Orbifold/wp-content/uploads/2021/04/OrbifoldLogo-300x78.pngOrbifold2014-09-03 15:51:012021-07-04 15:36:36Creating graphs in Mathematica
This is an overview of the discrete differential calculus on graphs with an emphasis on the usage of Mathematica to perform related calculations. While the calculus is more generic and can also be applied to generic simplices, it’s more complex to program since it involves concepts which are not directly deduced from the algebraic properties of graphs (e.g. orientation). We, hence, focus mainly on graphs and the usage of matrix methods.
Much of what is presented here is described in many ways and within various application domains. It’s probably new however to see it presented within Mathematica. This offers tremendous possibilities due to the calculational power and in the ways the various knowledge domains of Mathematica can be combined.
Creating graphs
Mathematica can easily output a wide spectrum of different graph types and offers lots of ways to customize and manipulate graphs. We will use in what follows a collection of graphs to highlight the discrete calculus and the examples below describe the various commands and notations.
Note: each of the gothic symbols L, T, G… can be executed and really are just aliases to Mathematica functions.
Example: a small, random directed graph.
The function R[ ] generates a random Bernoulli graph with five vertices and probability 0.5. You can change the default to produce something larger, e.g. R[12,0.3] produces a random graph with 12 vertices and probability of 0.3 for the edges;
Example: the cycle graph.
The gothic O will denote the cycle graph of ten vertices.
Example: the grid graph
The gothic G will denote the grid graph of five colums and three rows.
Example: the k-ary tree
The gothic T will denote the 3-ary tree of three levels.
Example: the linear graph of ten vertices.
The gothic L will denote the linear chain of ten vertices (9 edges).
Example: the complete graph
The gothic K will denote the complete graph over five vertices.
Matrices
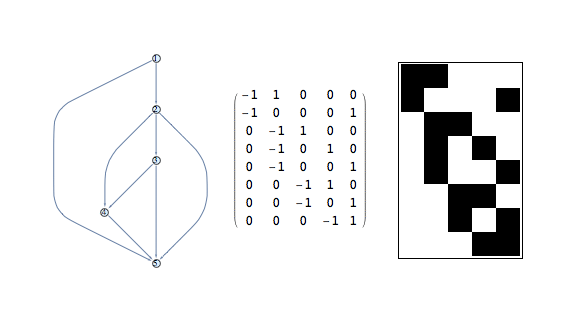
The notation or A[g] will denote incidence matrix of the graph g. Note that our incidence matrix is the edge-vertex matrix and not the vertex-edge matrix of Mathematica (i.e. the transposed).
Note that the incidence matrix is a sparse array and that if you wish to display it in a standard list you need to convert it using Normal or using MatrixForm for a standard matrix.
It’s important to note that the incidence matrix is not rectangular in general and acts more as a conversion operator from vertices to edges.
The notation or W[g] will denote the adjacency matrix of the graph g. The Mathematica implementation takes the directed edges into account but for our purposes the adjacency matrix needs to be symmetric.
The face-edge matrix B representing the incidence of edges with a face depends on the orientation one applies by hand on a face, i.e. a graph or simplex does not have a natural orientation induced by the edges. We assign an orientation to the T, G,… graphs based on the right-hand rule with the thumb point outwards the plane in which the graph resides.
Example: B face-edge matrix
The graph has one face and, hence, has a B matrix of one row
B = {{0,-1,1,-1,1,0}}
Note that the order of the B entries corresponds to the order of the edges defining the graph, which in this case is
{12,23, 24,35,45,56}
As a comparison, the is similar but has face edges all pointing in the opposite direction as the face orientation leading to
B = {{0,-1,-1,-1,-1,0}}
Chains and cochains
A 0-chain is vector defined on the vertices of the graph and 1-chain is a vector defined on the edges of the graph. Note that this is not the same as a function on the graph elements, it’s simply an algebra over the graph elements. A function on the vertices is a 0-cochain and is also a vector but it exists in a different space.
We will use
• σ1, σ2… to denote the 0-chains or vertices • τ1, τ2… to denote the 1-chains or edges • τ to denote the whole edge space (the list of all edges) • σ to denote the whole vertex space (the list of vertices)
For a given graph the makeChainBasis can be used to create the 0 and 1-chain basis elements. One can define higher order elments, like faces (2-chain) and volumes (3-chain) and we will use ocassionally the symbol φ1, φ2… to denote faces.
Example: chains
The 0-chains in the graph are generated (as a vector space) by the six basis elements {σ1, σ2, σ3, σ4, σ5, σ6} and the 1-chains by {τ1, τ2, τ3, τ4, τ5, τ6}.
The 0-chain
η = 2 σ1 + 4 σ3 + σ5
corresponds to
{2,0,4,0,1,0}
in the order of the vertices that the graph was defined.
The 1-chain
ζ = 3 τ3 + 7 τ6
corresponds to
{0,0,3,0,0,7}
in the order of the edges that the graph was defined. The linear combination of all vertices σ and the linear combination of all edges τ can be considered as the whole vertex space and edge space respectively.
Dual to the notion of chain are cochains which can be considered as discrete functions on the discrete elements. A 0-cochain is essentially a function on the vertices, a 1-cochain a function on the edges and so on. We will use • s1, s2… to denote the 0-cochains or vertex function • t1, t2… to denote the 1-cochains or edge functions
To generate a symbolic (vertex and/or edge) function on a given graph the makeVertexFunction and makeEdgeFunction can be used.
Example: creating symbolic graph functions
A vertex function f has five entries
{f1,f2,f3,f4,f5}
and can be created by means of
Similarly, an edge function has four components
{g12,g23,g24,g45}
create using
Inner product, metric and volume
The inner product defines a pairing between chains and cochains. Conversely, one can look at cochains as duals of the chains. On the zero-th level this means that if η and ζ are chains
< ζ | η > = ∈ R or C
The inner product of the basis elements is defined through a metric
= .
On the edge level a similar inner product can be defined with a different metric. So, contrary to the continuous case, one can have a hierarchy of metrics and inner products (of different dimensions since the vertex count is not necessarily the same as the edge count). We will denote by G the metric without specifying the level, the context making clear whether we deal with the metric on a vertex, edge or face level.
The metric can both be seen as a coupling factor in the inner product and as a weight on the vertices and edges. Especially on the edge level it’s interesting that the metric can be taken from the weight of the weighted graph. This means that the metric is usually taken as to be a diagonal matrix with orthogonality; only edge-edge and vertex-vertex coupling are considered.
Much like the continuous calculus you can then go back and forth between chains and cochains of the same level, i.e. for a given edge τ we define the cochain c
c = G τ
and conversely, with a cochain f we associate a chain π
π =
This implies that that cochains have an inner product defined as
< f | g > =
Example: metric and weighted graphs
Taking a random graph with random weights assigned to the edges we can form the edge-metric by means of the edgeMetric function, giving for instance the following
g = RandomGraph[{7,7},graphDesign,EdgeWeight→RandomInteger[100,7]] edgeMetric[g]//MatrixForm
The vertex metric can be created similarly with the vertexMetric function.
Because the metric is diagonal and the duality of chains and cochains we can define the inner product of a cochain f with a chain π as follows
< f | π > =
which can also be seen as the inner product of two vectors since the chain and cochain spaces are finite.
Finally, the volume of a chain is defined as
Vol = G. 1
which corresponds in the continuous case to the Hodge dual of one. So, if an integraion of a 1-cochain over an unweighted graph corresponds to
while a weighted graphs yields
Note that if the metric is normalized to Tr(G) = 1 this amounts to the expectation value of f if the metric is seen as a probabilistic distribution.
Example: edge and vertex volume of a random graph
g = RandomGraph[{7,7},graphDesign,VertexWeight→RandomInteger[100,7]]; edgeVolume[g] vertexVolume[g]
would give something like
{30,42,35,92,16,73,83} {1,1,1,1,1,1,1}
Integral, boundary and differential operators
We define the integral of a cochain c over a chain η to be equal to the inner product of c and so that the integral of a cochain c over a chain η is
= < c | η >
The boundary operator is defined as
∂ = for a 1-chain ∂ = for a 1-chain
which are in fact the only way that the respective matrices can be used to transform one type of vector to another (of a different dimension in general).
Example: the boundary operator
Let g be the graph and recall that the B matrix for this graph is
{0,-1,1,0,0,0} while the A matrix is
Because there is only one face it means that the boundary of this face is the same as B considered as a vector rather than a matrix. This indeed corresponds to the four edges with a sign indicating whether it’s traversed in the same or opposite direction.
Taking a 1-chain η = τ1+τ2+τ4 = {1, 1, 0, 1, 0, 0} the boundary is
∂η = {-1,0,0,0,1,0}
which corresponds to σ5 – σ1 and are indeed the endpoints of the line (sub)graph between vertices 1 and 5.
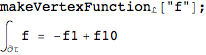
If we take the integral of a vertex function over the boundary of the full linear chain L we get the difference between the endpoints;
This is in essence the fundamental theorem of calculus in the graph context. A consequence of this is that any loop integral is zero. Of course, the general case is not always comparable to the coninuous calculus.
Example: integral over the grid graph
Since the cycle graph has no boundary, it’s obvious that the integral always gives zero. The discrete calculus is more general than just graphs and embraces simplices in general. If we would includes 2-chains or higher order elements we could show that in general the boundary of a boundary is zero. Mathematica does not have a simple function to output higher order boundary operators (like the IncidenceMatrix) and it would also require the concept of orientation.
The coboundary (derivative) d of a cochain is defined as the transpose of the boundary operator
∂ = for a 1-chain ∂ = for a 1-chain
which is again the only way one can, in fact, turn a vector from one space into another taking the underlying topology of the graph into account.
From a strict mathematical point of view the coboundary operator would be introduced in analogy to the continuous case:
< ∂σ | f > = < σ | df >
which is obviously true in this case since the respective matrices are transpose of each other.
Example: integral of a differential over L
Taking the linear L this leads to the usual difference
So, the integral over the linear chain of the differential of the function f is the difference between the endpoints, as should be.
Of course, this is by construction true for any graph and not just the linear chain. So, we have Stoke’s theorem for the discrete calculus
for arbitrary graphs. The extension to higher order chains and cochains is easily done theoretically but more difficult to implement in Mathematica, as said earlier, due to the need for orientations on a simplex or chain.
The differential of the 0-chains is not always a basis of the 1-chains, as is the case in the continuous calculus. For example, the graph has dσ1 + dσ2 + dσ3 = 0.This is also apparent from the fact that the incidence matrix as a rank one eigenspace. It can be easily shown that the egenspace has rank (m-n+1) with m edges, n vertices. So in this case we have effectively a cycle (when disgarding the direction of the edges).
The boundary and coboundary operators are nilpotent as should be
and
corresponding to
.
Div, Grad and Laplacian
The gradient of a scalar (0-cochain) u is defined as
∇ u ⇔ A u
which again is the only meaningful way in which one vector space element can be transformed to another. Also note that this corresponds to the differential du which is identical in the continuous context.The divergence of a vector (1-cochain) v is similarly defined as
∇.v ⇔
Taking the divergence of a gradient leads to the Laplacian and is hence equal to
Δ ⇔
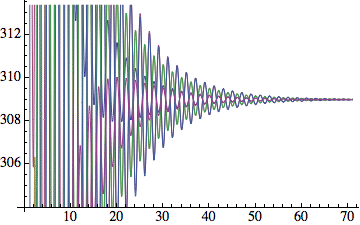
Example: diffusion on the triangle graph
The discrete diffusion equation on a graph with discrete time can be written as
u(t+1) = u(t) – α Δu(t)
where α acts as a diffusing coefficient from a vertex to its adjacent vertices. This can be taken as the edge weights or a global constant. If we take for example the following random initial state on the triangle graph
we get an equillibrium state after an initial oscillatory transition
but much depends on the initial state and the diffusion coefficient used.
It can be shown that the Laplacian satisfies
Δ = D – W
and hence that a stable state means that (
= meaning that the value at a vertex is the average of the values of its neighbors.
Non-commutative differential algebra
Diifferential structures on discrete sets are never far off from non-commutative algebras and intriguing relationships with stochastics, KdV and other equations. Contrary to the continuous settings one can have many differential structures and topologies on a discrete ‘manifold’.
The vector space of 1-cochains can be turned into a bi-algebra by means of the multiplication ◦ of a 0-cochains f and g as
(f ◦ = = ( = =
which turns it into a non-commutative algebra with commutator
[dg, f] =
so that
∫ [f,df] =
which is often referred to as the energy of graph. In a more refined analysis one could proof that when one goes to a continuous limit the commutator vanishes and thus recover the de Rham calculus. Symbolically
Note that the Leibniz property and other differential properties are satisfied
d(fg) = df ◦ g + f ◦ dg = Af . g + f . Ag
due to the fact that the incidence matrix transfers a vertex function to a difference across the edges.