
We all leave traces of our activity online and use more and more devices for entertainment and professional purposes. Browser cookies, IP address, location info…are routinely recorded and processed by tons of companies trying to figure out who you are, what you do, where you have been and most importantly how to influence your behavior. There are two opposing forces operating in this pool of data. On the one hand, marketing (and similar) companies try to figure out our activity online in order to fine tune ads and other influences. On the other hand, apps and companies help us to hide as much as possible by means of clever tricks and tools (e.g. iCloud Private Relay). It’s a cat and mouse game. In some domains like fraud prevention and anti-terrorism this is not so much a game as a vital activity to keep the world safe.
Entity resolution approach helps companies make inferences across vast volumes of information in enterprise systems and applications by bringing together records that correspond to the same entity.
Although you leave plenty of crumbles behind when visiting sites and places, trying to consolidate all this into something that reflects you as an identity or user is far from easy. For example, if you visit Amazon (without being logged in) on your phone while commuting your location info can’t reliably be used to identify you. Can an IP address be used and how to define distance (a metric) in the space of IP addresses. Nowadays plenty of websites ask a confirmation to see whether you are the same user if they detect anomalies in your location or device used, even if you have the right credentials. Trying to figure out who you are and whether new evidence can be mapped to you is referred to as ‘entity resolution’. The growth of services and diversity in devices has boosted this domain into a major business activity, similar to fraud detection and spam detection. The sophistication in techniques parallels the sophistication of criminal online acivity.
Basic entity resolution doesn’t have to be high-tech however. Some datasets and schemas can be approached with fairly simple techniques. You don’t always have to go straight to graph embeddings and advance graph machine learning. Entity resolution on a graph level corresponds to predicting edges on the basis of harvested user trails. If you want to learn from the payload contained in the nodes you would typically use GraphSAGE or node embedding techniques (using StellarGraph or PyG). A more shallow but faster and often good-enough approach is to use standard graph analytics and learn only from the topological information (i.e. ignore the payload of the nodes and edges).
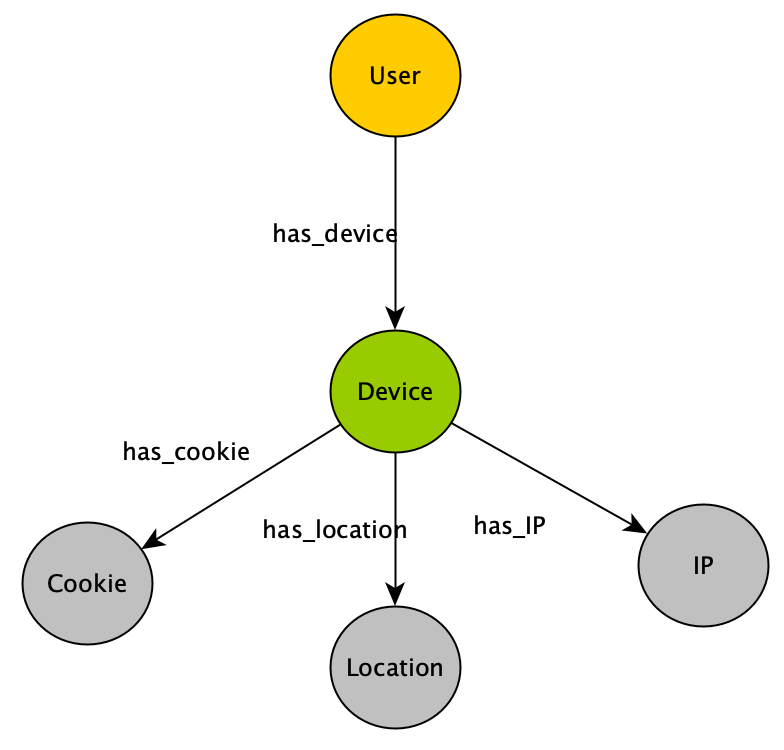
Let’s take a simple schema where a device is detected together with its IP address and cookies. If the user or identity is known (via login or other) the device used can be linked to the user. If the same user uses another device without login the question is how to link with some confidence (read: probability) this device to the known user. That is, how can the edge between the existing user node and the device node be predicted?
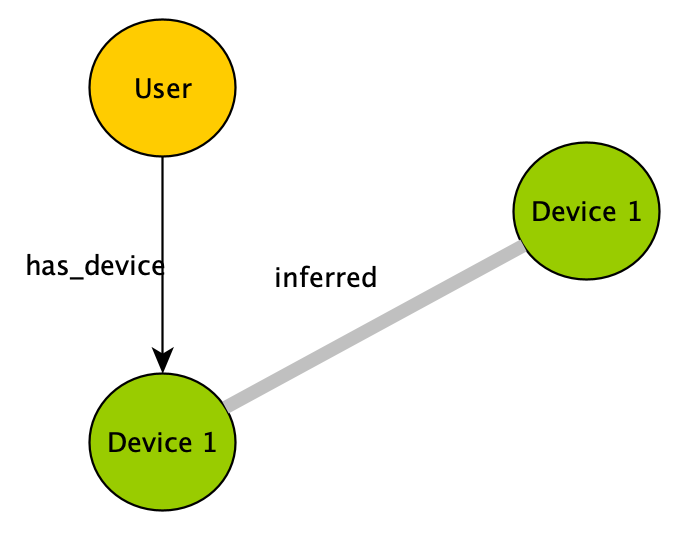
Of course, without any overlap there is no correlation. Depending on the business context you can use whatever makes sense to infer things. Let’s say the location is the same. The ‘same’ is something you need to define in your specific case. Technically it often amounts to defining a metric in the feature space under consideration. The representation below where the location is shared by two devices is created by means of data augmentation. Prior to creating nodes and edges there is some feature engineering cleaning the incoming data, trying to transform it (geolocation of IP address e.g.) and storing it according to the schema. Whether you use a semantic store or a property graph makes a big difference here. Unicity of nodes is automatic in triple stores while this has to be manually enforce in property graphs (specifically, in Neo4j).
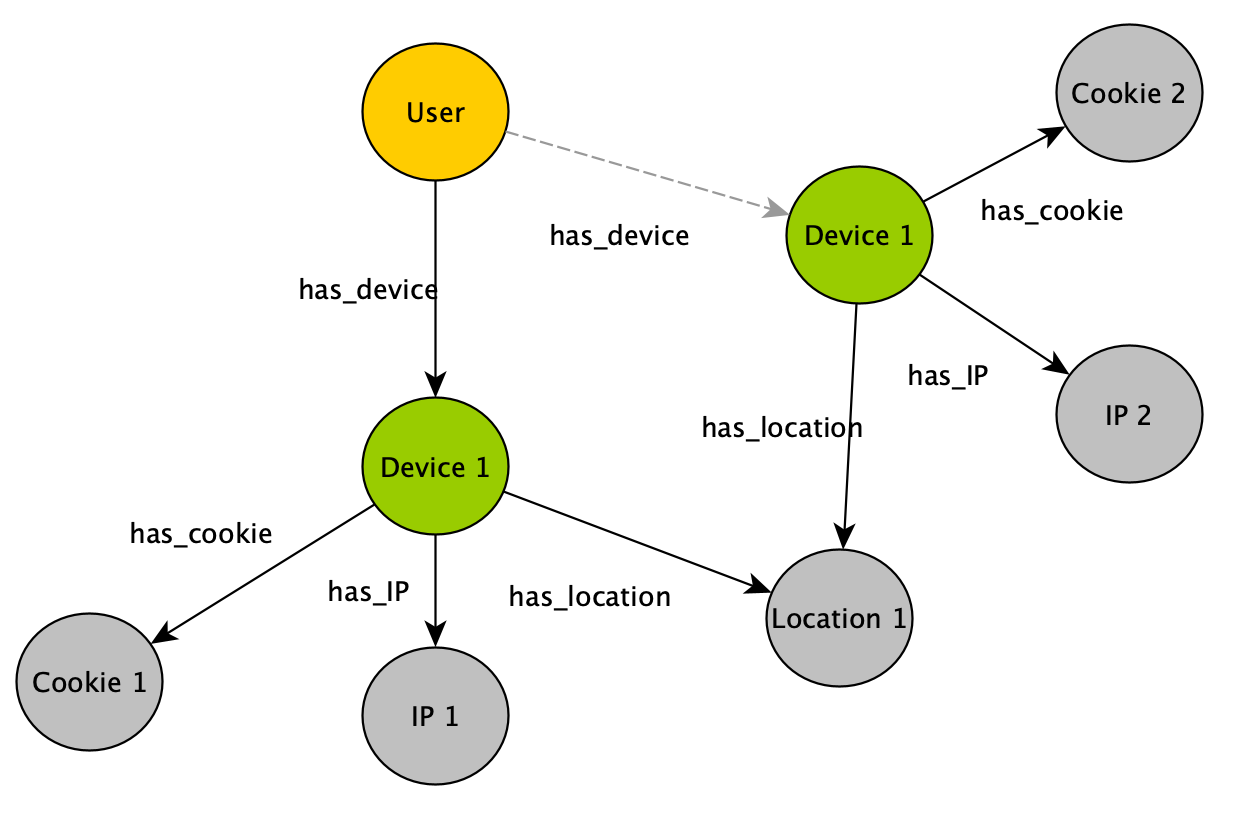
The standard approach is to reduce the raw graph by replacing shared information with edges like in the adjacent image. Ones device nodes are linked trough some measure/probability of affinitiy and one of the devices has an identiy, it’s just a matter of cluster things to the known user. The more two devices share nodes, the more likely they are from the same user.
If you transform gradually your raw data to a reduced graph where only identity nodes and device nodes remain the link prediction problem becomes trivial. In some cases you can even shortcut the effort by means of well-known link prediction algorithms like the Jaccard index, Adamic Adar or Soundarajan and Hopcroft.
We have found in multiple cases/projects that the (purely topological) approximation without taking the node payload intoc account is sufficient for most customers. Though in some cases you do need to apply advance machine learning, it comes with a hefty amount of processing and infrastructure.
It should also be noted that if your graph spans millions of nodes there is the marvelous rapids.ai package which easily handles really big graphs. It does not contain graph machine learning but you will find [the aforementioned topological link prediction algorithms](https://docs.rapids.ai/api/cugraph/nightly/api_docs/link_prediction.html).
If you want to discuss your particular entity resolution problem, drop us a line.