Memgraph is a very promising product and I sincerely hope it will mature in the coming years to become an enterprise-ready alternative to Neo4j. I must admit, I really like it. It’s not battle-ready and much in flux but if the Memgraph guys manage to elevate it, it will be stellar.
Before highlighting the objective pro and cons, let me mention the things that I find seducing:
they have an amazing collection of articles, not just about Memgraph but about lots of tangential topics.
their Discord channel is quite active and the Memgraph folks are highly responsive
the strategic choices are just right: the technology, the forward-looking features, the focus on developer features and Cypher as a query language.
Memgraph is also a lot of fun, it invites one to explore and to dive into all sorts of graph applications.
That said, I would not advise any customer to use it. Not yet. After using it for quite a while and in various ways, it’s clear that it will take a few years more to become a good alternative to Neo4j and to effectively do what the documentation mentions. For example, there are tons of articles on all sorts of graph analytic topics but many functions (e.g. cycle detection and other Mage methods) are not properly working. Things also often seem to break down when the graph becomes larger than a few thousand nodes. I did try out, for instance, to analyse the Hetionet dataset (around 2M edges) but it failed miserably. The Memgraph people are helpful but it’s clear it all requires some more TLC.
The same goes for the hosted version, Memgraph Cloud. Various things fail, connections drop randomly and I would not suggest any customer to use it for their running business. Again, I do believe it’s going in the right direction but it ain’t there yet.
On a more factual level, these are the things you need to consider when evaluating Memgraph:
Pro
Both MemGraph and Mage can run on GPU, it makes use of cuGraph (part of RapidsAI). This is a huge plus in comparison with Neo4j, which runs only ML stuff on CPU.
Mage sits outside the database, way better than the way Neo4j does ML inside the database. The support for Python out of the box is also a huge advantage if you are into graph machine learning.
Really good and extensive documentation.
GQLAlchemy is an Object-Graph Mapper (OGM) which also works with Neo4j.
Fast, in-memory with transactions written to disk.
Custom procedure in Python, rather than Java. C++ is also supported.
Because the query language can be via Python it made it possible to integrates NetworkX. You can use NetworkX functionality and in this way extends the library to a graph database rather than just for small graphs
Single database, one graph. Not multi-tenant and if you want another graph you need to dump the current one.
In-memory means at any instant you have a very fast graph but it’s just one single graph
No schema support. No ontology enforced. In this respect, TigerGraph remains pretty much the only (property graph) database doing it right.
Linux only with MacOS and Windows via Docker.
Low adoption but growing.
Small but strong community support
Limited query profiling
Missing enterprise breadth and technical solutions (like CDC)
None of the disadvantages are necessarily an issue but the fact that listed features are not always working or fail on (not very) large graphs is something to take serious.
MemGraph is a fantastic graph database with a bright future, it implements OpenCypher and can be an in-place replacement for Neo4j if you are willing to overlook some growing pains. It’s a typical open source (C with serious investors (Microsoft among others) and comes with streaming analytics and heaps of really nice documentation.
The biggest drawback (at this point in time, at least) is the one-database limitation. It holds the graph in memory making it very fast and enabling streaming analytics. Memgraph continuously backs up data to disk with transaction logs and periodic snapshots. On restart, it uses the snapshot and log files to recover its state to what it was before shutting down. So, unlike RedisGraph for instance, in-memory does not mean the data is volatile.
Besides speed, the Python/C++ stack means that writing custom procedures can be written in Python and NetworkX is part of the query language. This is huge productivity gain and appeals to data scientists. Neo4j does not run on GPU and implements its machine learning within the database. Both points render Neo4j weak in a data science context. MemGraph, on the other hand, does run on GPU and its Mage extensions runs outside the database.
The code in this article can be found in this Colab notebook .
NetworkX is a graph analysis library for Python. It has become the standard library for anything graphs in Python. In addition, it’s the basis for most libraries dealing with graph machine learning. Stellargraph, in particular, requires an understanding of NetworkX to construct graphs. Below is an overview of the most important API methods. The official documentation is extensive but it remains often confusing to make things happen. Some simple questions (adding arrows, attaching data…) are usually answered in StackOverflow, so the guide below collects these simple but important questions.
General remarks
The library is flexible but these are my golden rules:
do not use objects to define nodes, rather use integers and set data on the node. The layout has issues with objects.
the API changed a lot over the versions, make sure when you find an answer somewhere that it matches your version. Often methods and answers do not apply because they relate to an older version.
if you wish to experiment with NetworkX in Jupyter, go for Colab and use this stepping stone:
!pip install faker
import networkx as nx
import matplotlib.pyplot as plt
from faker import Faker
faker = Faker()
%matplotlib inline
Creating graphs
There are various constructors to create graphs, among others:
# default
G = nx.Graph()
# an empty graph
EG = nx.empty_graph(100)
# a directed graph
DG = nx.DiGraph()
# a multi-directed graph
MDG = nx.MultiDiGraph()
# a complete graph
CG = nx.complete_graph(10)
# a path graph
PG = nx.path_graph(5)
# a complete bipartite graph
CBG = nx.complete_bipartite_graph(5,3)
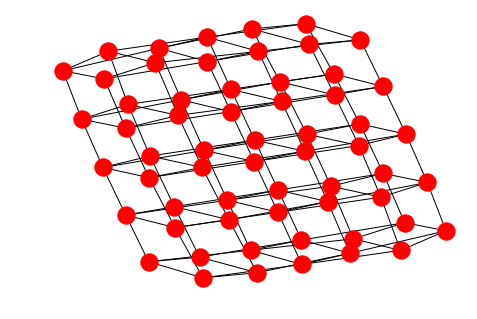
# a grid graph
GG = nx.grid_graph([2, 3, 5, 2])
Make sure you understand each class and the scope of each. Certain algorithms, for instance, work only with undirected graphs.
Graph generators
Graph generators produce random graphs with particular properties which are of interest in the context of statistics of graphs. The best-known phenomenon is six degrees of separation which you can find on the internet, our brains, our social network and whatnot.
Erdos-Renyi
The Erdos-Renyi model is related to percolations and phase transitions but is in general the most generic random graph model. The first parameter is the amount of nodes and the second a probability of being connected to another one.
er = nx.erdos_renyi_graph(50, 0.15)
nx.draw(er, edge_color='silver')
Watts-Strogratz
The Watts-Strogratz model produces small-world properties. The first parameter is the amount of node then follows the default degree and thereafter the probability of rewiring and edge. So, the rewiring probability is like the mutation of an otherwise fixed-degree graph.
The Barabasi-Albert model reproduces random scale-free graphs which are akin to citation networks, the internet and pretty much everywhere in nature.
ba = nx.barabasi_albert_graph(50, 5)
nx.draw(ba)
You can easily extract the exponential distribution of degrees:
g = nx.barabasi_albert_graph(2500, 5)
degrees = list(nx.degree(g))
l = [d[1] for d in degrees]
plt.hist(l)
plt.show()
Drawing graphs
The draw method without additional will present the graph with spring-layout algorithm:
nx.draw(PG)
There are of course tons of settings and features and a good result is really dependent on your graph and what you’re looking for. If we take the bipartite graph for example it would be nice to see the two sets of nodes in different colors:
from networkx.algorithms import bipartite
X, Y = bipartite.sets(CBG)
cols = ["red" if i in X else "blue" for i in CBG.nodes() ]
nx.draw(CBG, with_labels=True, node_color= cols)
The grid graph on the other hand is better drawn with the Kamada-Kawai layout in order to see the grid structure:
nx.draw_kamada_kawai(GG)
Nodes
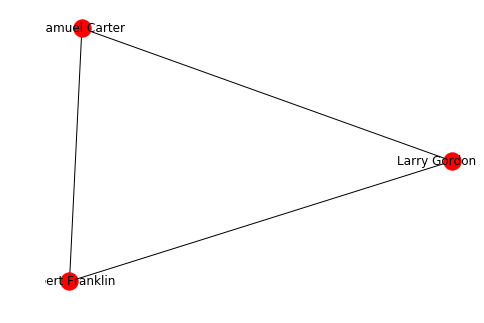
If you start from scratch the easiest way to define a graph is via the add_edges_from method as shown here:
from faker import Faker
faker = Faker()
class Person:
def __init__(self, name):
self.name = name
@staticmethod
def random():
return Person(faker.name())
g = nx.Graph()
a = Person.random()
b = Person.random()
c = Person.random()
g.add_edges_from([(a,b), (b,c), (c,a)])
# to show the names you need to pass the labels
nx.draw(g, labels = {n:n.name for n in g.nodes()}, with_labels=True)
As mentioned earlier, it’s better to use numbers for the nodes and set the data via the set_node_attributes methods as shown below.
Edges
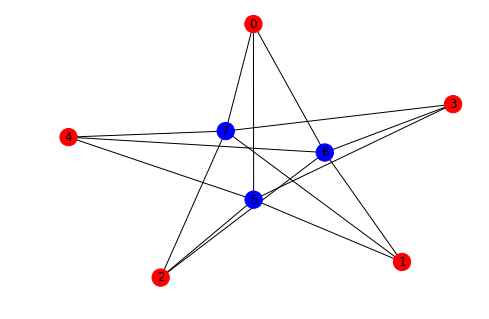
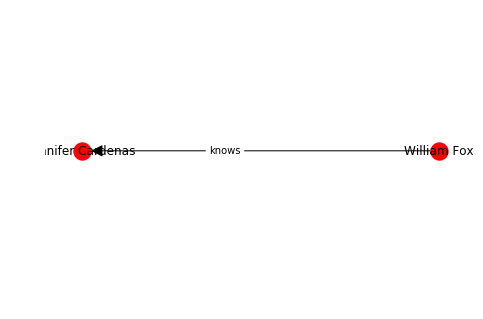
Arrows can only be shown if the graph is directed. NetworkX is essentially a graph analysis library and much less a graph visualization toolbox.
G = nx.DiGraph()
a = Person.random()
b = Person.random()
G.add_node(0, data=a)
G.add_node(1, data=b)
G.add_edge(0, 1, label="knows")
labelDic = {n: G.nodes[n]["data"].name for n in G.nodes()}
edgeDic = {e: G.get_edge_data(*e)["label"] for e in G.edges}
kpos = nx.layout.kamada_kawai_layout(G)
nx.draw(G, kpos, labels=labelDic, with_labels=True, arrowsize=25)
nx.draw_networkx_edge_labels(G, kpos, edge_labels=edgeDic, label_pos=0.4)
Analysis
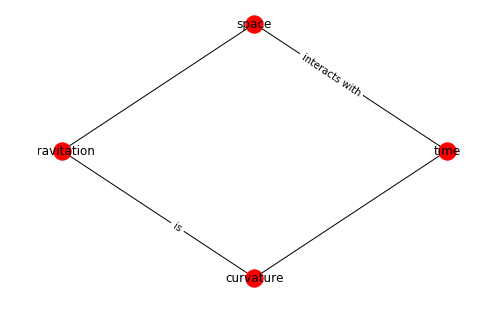
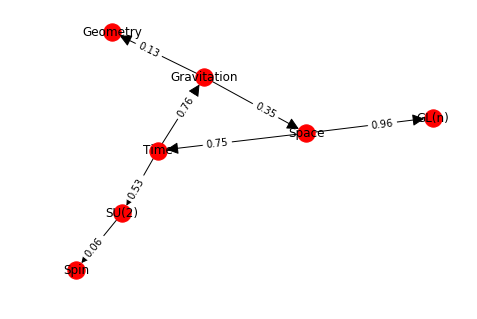
There many analysis oriented methods in NetworkX, below are just a few hints to get you started. Let’s assemble a little network to demonstrate the methods:
import random
gr = nx.DiGraph()
gr.add_node(1, data={'label': 'Space'})
gr.add_node(2, data={'label': 'Time'})
gr.add_node(3, data={'label': 'Gravitation'})
gr.add_node(4, data={'label': 'Geometry'})
gr.add_node(5, data={'label': 'SU(2)'})
gr.add_node(6, data={'label': 'Spin'})
gr.add_node(7, data={'label': 'GL(n)'})
edge_array = [(1, 2), (2, 3), (3, 1), (3, 4), (2, 5), (5, 6), (1, 7)]
gr.add_edges_from(edge_array)
for e in edge_array:
nx.set_edge_attributes(gr, {e: {'data':{'weight': round(random.random(),2)}}})
gr.add_edge(*e, weight=round(random.random(),2))
labelDic = {n:gr.nodes[n]["data"]["label"] for n in gr.nodes()}
edgeDic = {e:gr.edges[e]["weight"] for e in G.edges}
kpos = nx.layout.kamada_kawai_layout(gr)
nx.draw(gr,kpos, labels = labelDic, with_labels=True, arrowsize=25)
o=nx.draw_networkx_edge_labels(gr, kpos, edge_labels= edgeDic, label_pos=0.4)
Getting the adjacency matrix gives a sparse matrix. You need to use the todense method to see the dense matrix. There is also a to_numpy_matrix method which makes it easy to integrate with numpy mechanics:
If you need to use the edge data in the adjacency matrix this goes via the attr_matrix:
nx.attr_matrix(gr, edge_attr="weight")
Simple things like degrees are simple to access:
list(gr.degree)
The shortest path between two vertices is just as simple but please note that there are dozens of variations in the library:
nx.shortest_path(gr, 1, 6, weight="weight")
Things like the radius of a graph or the cores is defined for undirected graphs:
nx.radius(gr.to_undirected())
nx.find_cores(gr)
Centrality is also a whole world on its own. If you wish to visualize the betweenness centrality you can use something like:
cent = nx.centrality.betweenness_centrality(gr)
nx.draw(gr, node_size=[v * 1500 for v in cent.values()], edge_color='silver')
Getting the connected components of a graph:
nx.is_connected(gr.to_undirected())
comps = nx.components.connected_components(gr.to_undirected())
for c in comps:
print(c)
Clique
A clique is a complete subgraph of a particular size. Large, dense subgraphs are useful for example in the analysis of protein-protein interaction graphs, specifically in the prediction of protein complexes.
def show_clique(graph, k = 4):
'''
Draws the first clique of the specified size.
'''
cliques = list(nx.algorithms.find_cliques(graph))
kclique = [clq for clq in cliques if len(clq) == k]
if len(kclique)>0:
print(kclique[0])
cols = ["red" if i in kclique[0] else "white" for i in graph.nodes() ]
nx.draw(graph, with_labels=True, node_color= cols, edge_color="silver")
return nx.subgraph(graph, kclique[0])
else:
print("No clique of size %s."%k)
return nx.Graph()
Taking the Barabasi graph above and checking for isomorphism with the complete graph of the same size we can check that the found result is indeed a clique of the requested size.
red = nx.random_lobster(100, 0.9, 0.9) nx.draw(ba)
petersen = nx.petersen_graph()
nx.draw(petersen)
G=nx.karate_club_graph()
cent = nx.centrality.betweenness_centrality(G)
nx.draw(G, node_size=[v * 1500 for v in cent.values()], edge_color='silver')
Graph visualization
As described above, if you want pretty images you should use packages outside NetworkX. The dot and GraphML formats are standards and saving a graph to a particular format is really easy. For example, here we save the karate-club to GraphML and used yEd to layout things together with a centrality resizing of the nodes.
In the context of machine learning and real-world data graphs it’s important that nodes and edges carry data. The way it works in NetworkX can be a bit tricky, so let’s make it clear here how it functions.
G = nx.Graph()
G.add_edge(12,15, payload={'label': 'stuff'})
print(G.get_edge_data(12,15))
print(G.get_edge_data(12,15)['payload']['label'])
One can also set the data after the edge is added:
G = nx.Graph()
G.add_edge(12,15)
nx.set_edge_attributes(G, {(12,15): {'payload':{'label': 'stuff'}}})
print(G.get_edge_data(12,15))
print(G.get_edge_data(12,15)['payload']['label'])
Pandas
The library has support for import/export from/to Pandas dataframes. This exchange, however, applies to edges and not to nodes. The row of a frame are used to define an edge and if you want to use a frame for nodes or both, you are on your own. It’s not difficult though, let’s take a graph and turn it into a frame.
g = nx.barabasi_albert_graph(50, 5)
# set a weight on the edges
for e in g.edges:
nx.set_edge_attributes(g, {e: {'weight':faker.random.random()}})
for n in g.nodes:
nx.set_node_attributes(g, {n: {"feature": {"firstName": faker.first_name(), "lastName": faker.last_name()}}})
You can now use the to_pandas_edgeList method but this will only output the weights besides the edge definitions:
import pandas as pd
import copy
node_dic = {id:g.nodes[id]["feature"] for id in g.nodes} # easy acces to the nodes
rows = [] # the array we'll give to Pandas
for e in g.edges:
row = copy.copy(node_dic[e[0]])
row["sourceId"] = e[0]
row["targetId"] = e[1]
row["weight"] = g.edges[e]["weight"]
rows.append(row)
df = pd.DataFrame(rows)
df
FIRSTNAME
LASTNAME
SOURCEID
TARGETID
WEIGHT
0
Rebecca
Griffin
0
5
0.021629
1
Rebecca
Griffin
0
6
0.294875
2
Rebecca
Griffin
0
7
0.967585
3
Rebecca
Griffin
0
8
0.553814
4
Rebecca
Griffin
0
9
0.531532
…
…
…
…
…
…
220
Tyler
Morris
40
43
0.313282
221
Mary
Bolton
41
42
0.930995
222
Colton
Hernandez
42
48
0.380596
223
Michael
Moreno
43
46
0.236164
224
Mary
Morris
45
47
0.213095
Note that you need this denormalization of the node data because you actually need two datasets to describe a graph in a normalized fashion.
StellarGraph
The StellarGraph library can import directly from NetworkX and Pandas via the static StellarGraph.from_networkx method. One important thing to note here is that the features on a node as defined above will not work because the framework expects numbers and not strings or dictionaries. If you do take care of this (one-hot encoding and all that) then this following will do:
If NetworkX does not contain what you are looking for or if you need more performance, the iGraph packageis a good alternative and has bindings for C, R and Mathematica while NetworkX is only working with Python. Another very fast package is the Graph-Tool framework with heaps of features.
Beyond these standalone packages there are also plenty of frameworks integrating with various databases and, of course, the Apache universe. Each graph database has its own graph analytics stack and you should spend some time investigating this space especially because it scales beyond what the standalone packages can.
Finally, graph analytics can also go into terabytes via out-of-memory algorithms, Apache Spark and GPU processing to name a few. The RapidsAI framework is a great solutions with the cuGraph API running on GPU and is largely compatible with the NetworkX API.
https://graphsandnetworks.com/wp-content/uploads/2022/11/NetworkXLogo-1.png280280Orbifold/wp-content/uploads/2021/04/OrbifoldLogo-300x78.pngOrbifold2022-11-21 13:21:462022-11-22 08:51:29NetworkX: an overview