Spark GraphFrame Basics
Out of the box the Spark distribution does not contain the GraphFrames package. You simply need to download the jar from here and put it into the libexec\jars directory of the Spark download. Of course, restart the whole lot if already running. Whether the Pypi GraphFrames package for Python is needed is not clear to me.
Start Spark in the usual fashion
import findspark, os
from pyspark.sql import SparkSession
from pyspark import SparkContext
os.environ["JAVA_HOME"]="/Library/Java/JavaVirtualMachines/jdk1.8.0_202.jdk/Contents/Home"
print(findspark.find())
findspark.init()
sc = SparkContext.getOrCreate()
spark = SparkSession.Builder().appName('GraphFrames').getOrCreate()
and create a standard dataframe for both the nodes and the edges
from pyspark import SQLContext
sqlContext = SQLContext(sc)
nodes = sqlContext.createDataFrame([
("a", "Alice", 34),
("b", "Bob", 36),
("c", "Charlie", 30),
], ["id", "name", "age"])
edges = sqlContext.createDataFrame([
("a", "b", "friend"),
("b", "c", "follow"),
("c", "b", "follow"),
], ["src", "dst", "relationship"])
A graph frame is then simply a combination of these two frames
from graphframes import *
g = GraphFrame(nodes, edges)
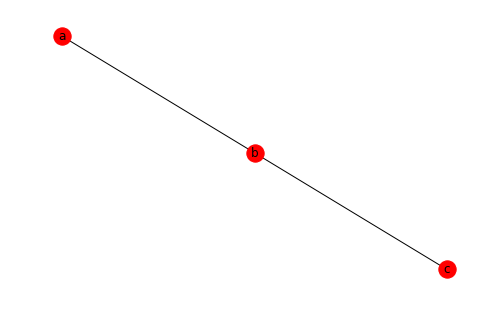
People often wonder whether you can render a GraphFrame graph. This only makes sense if your graph is ‘small’. Just like it does not make sense to convert terabyte Spark dataframes to a Panda frame, you should not attempt to think of big-data graph frames as something you can visualize.
Still, if you want to do it, just take the frame of edges and hand it over to NetworkX.
import networkx as nx
gp = nx.from_pandas_edgelist(edges.toPandas(),'src','dst')
nx.draw(gp, with_labels = True)
On the analytic side, you can from here on enjoy the whole GraphFrames API:
g.inDegrees.show()
+---+--------+
| id|inDegree|
+---+--------+
| c| 1|
| b| 2|
+---+--------+
including the page-rank algorithm
results = g.pageRank(resetProbability=0.01, maxIter=20)
results.vertices.select("id", "pagerank").show()
+-----+--------------------+
| id| pagerank|
+-----+--------------------+
| 14,6| 0.294145761242611|
| 10,5| 0.2022338632841195|
| 14,1| 0.07235944148922492|
| 0,15| 0.03654559907802415|
| 0,19| 0.03654604538590314|
| 2,18| 0.10774836041079427|
|12,17| 1.6440001759095513|
|10,19| 3.399398634973527|
| 9,11| 0.543782922230953|
| 16,2| 0.10746807938250608|
| 15,8| 0.6612202246354048|
| 4,8| 0.16755781414237972|
| 7,8| 0.23648950488934758|
| 0,12|0.036542159103863825|
|19,14| 9.203254033641397|
| 16,9| 0.9285135363356551|
|19,12| 6.099750937014576|
| 13,1| 0.07235119679030458|
| 2,16| 0.10746807938250608|
| 3,8| 0.13806308065786485|
+-----+--------------------+
only showing top 20 rows
The results of the pageranking can also be visualized with NetworkX, of course. Note that NetworkX has its own page-rank algorithm as well.
You can generate some predefined graphs via the example namespace
from graphframes.examples import Graphs
g = Graphs(sqlContext).gridIsingModel(20)
which looks like this
gp = nx.from_pandas_edgelist(g.edges.toPandas(),'src','dst')
nx.draw_spectral(gp, center=["2", "5"], scale=3.1)

When all is done, shut down your cluster:
spark.stop()