
An Introduction to Knowledge Representation
(This is six-part series on semantics and reasoning)
The world has moved over time from relational storage solution to NoSQL ‘not only SQL’ solutions thereby relaxing the need for strict schemas and foreign keys. The success of MongoDB is parlleling the success of JavaScript while strongly typed languages like Java and C# are more geared towards RDBMS. Nowadays you find hybrid solutions like SQLServer and CosmosDB offering a mix of graph features and relational ones thus fading the boundary between graphs and tables.
One type of storage that always has been around but never took much off (outside academia) is semantic storage and triple stores. Of course, you do find large efforts like DBPedia and biochemeical networks (the OBO foundry e.g.) but ontologies are still a curiosity in most enterprises. The reason for this is that, much like machine learning and AI, it has its roots in universities and through this a focus on research abstraction and generalizations rather than applications. If you look a bit into onologies and semantics you can easily discern what is written where; a lot of confusion arises from ontology research having difficulties to apply itself to mundane business challenges.
In this overview I want to present a collection of real-world findings you can apply today without having to go through a steep learning curve or a jungle of confusing research.
Semantics, ontologies and whatnot
The field is mined with confusing terminology; ontology, taxonomy, triple, thesaurus… Much like machine learning and other fields there are concepts which are used in the context of software development and concepts which sit in the conceptual domain.
Let me review a few things.
A thesaurus is a collection of concepts organized in a graph-like form.
The term ‘thesaurus’ is usually used in the context of publications and is a librarian’s term for organizing things. In fact, the related term taxonomy is often used to be synonnymous to thesaurus although, strictly speaking, it’s not the same.
A taxonomy is a collection of concepts organized in a tree-like fashion where a child is a special case of its parent.
In this sense, a ‘city’ is not sub-type of a ‘country’. Rather, a ‘country’ contains a ‘city’. A taxonomy is similar to the idea of class inheritance. An abstract class ‘vehicle’ can be a base class for a ‘car’ but it’s clear that this specialization is unrelated to the inclusion. In mathematical terms the poset defined by inclusion is unrelated to the poset defined through inheritance.
If we would take the concept ‘person’ as another example, the concept ‘student’ is a true sub-type of a person and so is the concept ‘retired person’. The concept ‘student’ is NOT part of (a subset of) the concept ‘person’. You don’t carry a student inside yourself. Well, not physically at least. So, in general, it’s not because something is contained in something else that it’s a sub-class.
Rather than speaking of ‘concepts’ one uses the term Class in the context of ontology-theory:
A Class is a concept, a type of object, a kind of something, stuff.
When you organize classes into a hierarchy you end up with a taxonomy. A sub-class is a specialization very much like one organizes things in object-oriented programming languages.
Since a hierarchy has a root one needs to have something which fits everything and anything. This is a ‘thing’. At the root of every taxonomy (and an ontology as we’ll see below) is a thing:
The thing is what can be used to describe any-thing and is the root of every-thing.
In the context of programming one would use Object rather than thing. Indeed, an Object in Java or any modern programming language is the root of any class hierarchy.
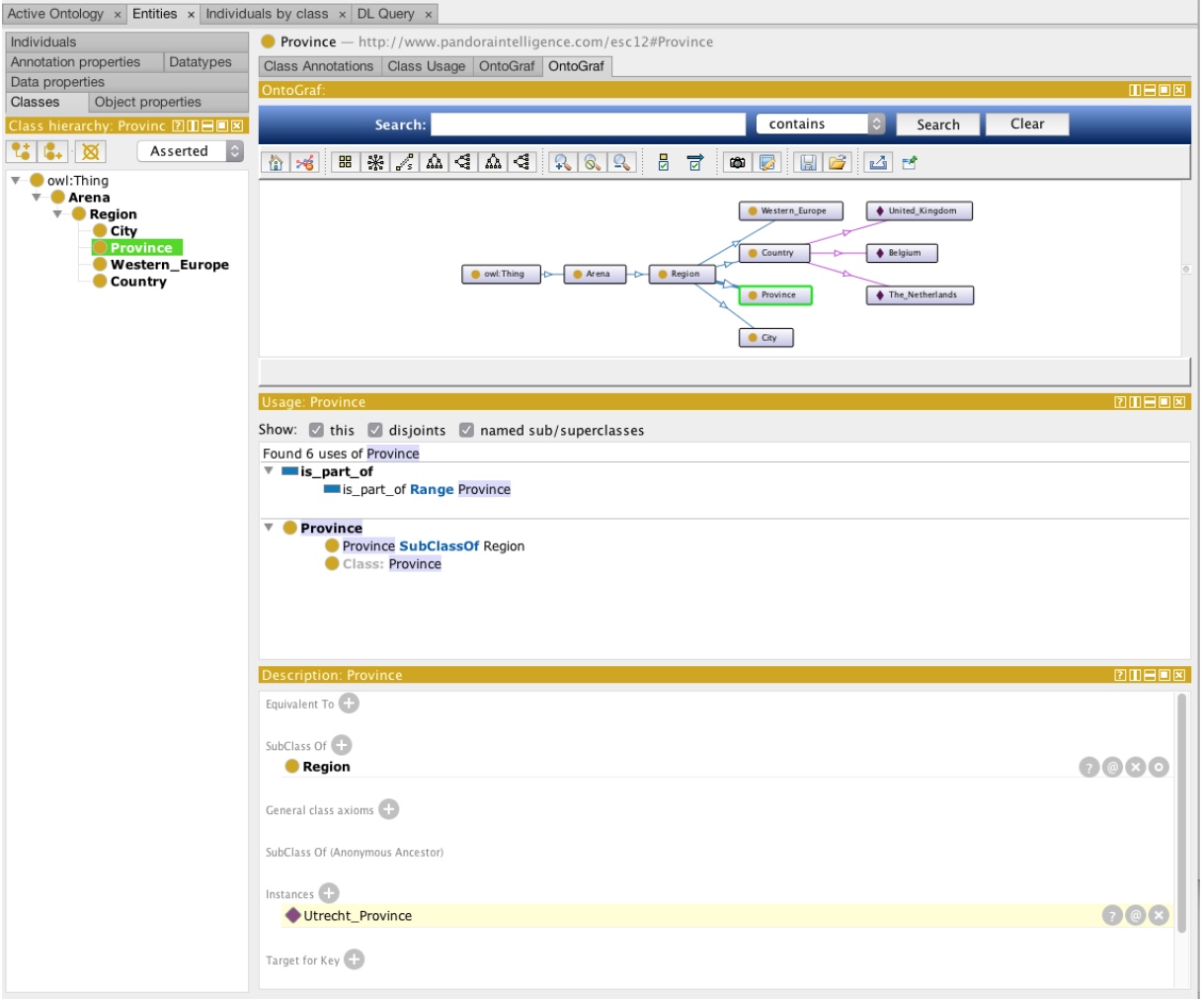
A basic taxonomy is hence:
- thing
- arena
- region
- city
- province
Note that ‘city’ does not sit under ‘province’ otherwise you would have to admit that a ‘city’ is also a ‘province’. Imagine you have a property of a ‘province’ called ‘the amount of cities contained in this province‘. This property makes sense for a ‘province’ but if you would put ‘city’ underneath it you would have to have this property for a city as well and this clearly doesn’t make sense.
Similarly, imagine you would put ‘feet’ underneath the class ‘person’. It would mean that ‘feet’ have all the properties of a ‘person’. Ain’t right.
Now, since one obviously wants to have the relaionships ‘person -> feet’ or ‘province -> city’ one has to go beyond the taxonomy. This is where ontologies enter:
An ontology builds on top of a taxonomy and adds things like relations, constraints, rules and, in general, anything you need to describe a domain of interest.
Taking our example above, you can in an ontology describe that ‘a city is part of a province‘ or that ‘feet are part of a person‘. You can also add a constraint stating that ‘a person has at most two feet’ or that ‘there is no province without at least one city‘.
Before diving deeper into ontologies I also need to highlight some more terminology and ideas:
- a Class (entity, concept) is an abstract thing of which there are many instances. For example, the class ‘person’ can have ‘John Field’ as an instance. It’s an example of an abstract concept. It’s often called an individual. The term in ‘instance’ is akin to the idea of an instance in OOP (object-oriented programming)
- a Class has properties. A ‘country’ has an area, a population and so on. One makes a distinction between properties which are actually classes themselves and properties which are basic data types. The former is called an object property and the latter a data property. So, the area of a country is a data property while the collection of provinces is an object property.
- a Class has annotations. Call it informative metadata. It does not influence the rest of the story, it’s just useful for people to read about or if you wish to render an ontology as a document.
- properties are often called attributes. The term ‘attribute’ stems from the way a property is captured in XML, as explained below.
Where things become more technical
Obviously, all of the above terminology and ideas can be captured in a well-defined shape and is regulated by strict rules. The way one captures an ontology is through the Resource Description Framework (RDF):
RDF is a way (language, format) to build a vendor-neutral and operating system-independent system of metadata about some knowledge domain. It looks like XML.
It’s the language you use to pin down an ontology. Since it’s a knowledge domain itself there is also a language to describe RDF and this is called RDF Schema (RDFS) but we’ll not go into this.
How does RDF look like? It’s just a special type of XML. Elements of RDF are prefixed with the lower-case ‘rdf’. For instance, you have things like
- rdf:Class
- rdf:DataType
- rdf:Individual
and so on. Since people seldom actually write XML (did you know that a Word document is XML?) there are tons of tools to support this. This is where ontology-theory turns into business-as-usual. Before showing you how things look like I should emphasize the well-known wisdom that
the great thing about standards is there are so many to chose from…
The RDF framework is not the only way to frame an ontology:
- the Web Ontology Language (OWL) is a very popular alternative is fully compatible with RDF(S)
- because the (technology) world has turned more and more away from XML there is a JSON format which sits closer to scripting programming languages (say, JavaScript). The JSON-LD format (JavaScript Object Notation for Linked Data) captures ontologies in a way that is more digestible to browsers and scripting tools.
- because RDF is quite verbose there is also a equivalent but more readable Turtle format
- since the advent of big-data and a plathora of tools to store large amounts of ontologies and data, there are also more database-like formats. Things like triple-stores, quadruple stores and whatnot are ways to store individuals (instances) of ontologies.
What you should take away from this is that:
- there is an academic world dealing with ontologies and they use a set of formats and terms
- there is a software industry implementing tools to deal with ontologies (and articulate businesses atop it) and they use related formats and terms
Remember that an instance or Individual is a concrete example of an abstract Class. If you take the whole graph of Classes and relating things you get an Ontology. In the same way, if you take a whole lot of Individuals and there relationships (constraints, rules…) you get a Knowledge Graph. A knowledge graph is the instantiation of an ontology, if you wish.
A knowledge graph adheres to strict rules defined in an ontology.
Since every (intellectual) domain has its own terminology and structure you have ontologies all over the place. For example:
- the BioPortal contains 8.3 million (!) classes describing everything related to biochemistry and cellular structure
- the Dublin Core is an international effort to describe publications, books, works of art and so on
- an effort to combine ontologies of ontologies and thus to map out the whole world, SUMO: Suggested Uper Merged Ontology
Of course, if you look a bit around you will also find ontologies to describe tweets, Wikipedia articles, the DBPedia ontology and pretty much everything.
The thing that you should take away from this is this:
if you know the ontology of some body of data you can navigate through it.
The reason why so much effort has been put into biological ontologies is because cancer research can be combined no matter what the underlying implementation is. Similarly, if you look at the Wikipedia ontology you know each and every constituent in a Wikipedia article.
One can also combine ontologies but how does one ensure that you don’t have name clashes? The answer resides in the Uniform Resource Identifier (URI). Imagine we start to formally pin down an ontology, we need to fix the URI of this ontology. Typically one uses an HTTP for this. So, we would have classes like
but maybe also a proprietary ontology related to fuel and gas:
Note that these are NOT addresses on the web, these are labels to differentiate our domain of expertise. However, if we would wish to combine our knowledge with Wikipedia we would only have to use the Wikipedia ontology to navigate to the properties of interest. That is, you don’t need to figure how things are structured, the ontology tells you this and the concrete data is guaranteed to have this structure.
How to knit an ontology
Creating an ontology is a game you need to play on two levels: domain expertise and RDF structure. You need to comprehend what you are talking about and develop a network of classes correspondingly. The network infers questions about the domain and the domain forces you to think about the best way to structure things within the constraints of RDF, OWL or whatever standard you like.
Luckily there is a great piece of software to help you out. Download the free Protégé app from Stanford and have some fun. Go and download it and you will learn a great deal about ontologies.
What you should note:
- you have a simple yet effective interface to create individuals, classes, properties and attributes
- there is a graphical (diagram) interface which helps to navigate across (large) ontologies
- it supports refactoring (e.g. moving or renaming things)
- you can export/import to and from various sources
The tool also includes useful examples of ontologies (food, people, travel, wine…) from which you can learn.
There is a delightful Ontology Development 101: A Guide to Creating Your
First Ontology which can help you taking the first few steps.
You might wonder: why do I need to develop an ontology if I can store triples straight away? The situation is similar to MongoDB: you can store any JSON in MongoDB and if you don’t think in advance about the global structure you end up with a heap of JSON you cannot manage. Data without structure is useless. Similarly, you can push any quad or triple into a semantic store but without an ontology you end up with a massive graph you cannot use.
An ontology is a schema for your triples.
How strict you are with enforcing the ontology on your data is up to you. Usually it’s quite hard to not allow some flexibility. The more the data does follow the schema, however, the more you can query the data with confidence and the more you can be sure that there are not orhpan or duplicate concepts. Indeed, imagine you do not fix the relationship ‘friend’ in your data. Maybe you start with ‘is_a_friend‘ but then some time later you start using ‘is_friend‘ and someone else is using ‘has_friend‘ and so on. Eventually, you have a social network but you cannot query it with confidence. So, make sure you do enforce some uniformity in naming predicates and classes.
Creating a good ontology is an art on its own, especially if you try to cover large domains (say, oncology). The same can be said about large relational databases (say, running social security business on a mainframe DB2). It comes with experience.
Inference: extracting insights
A friend of a friend is a friend. This transitiveness of a partially ordered set translates in ontologies to inference. That is, if you specify that a relation (a predicate) is transitive the software can apply it to your data. This ‘applying’ thus depends on two things; properly defining the relationships and the underlying software.
The business of inferring knowledge is a domain on its own; different storage systems have different implementations, performance and quality can vary widely. The easiest way to see it in action is however inside Protégé.
Inside the Protégé tool you can also find a couple of reasoners and you can also immediately see in the interface stuff that’s being inferred.
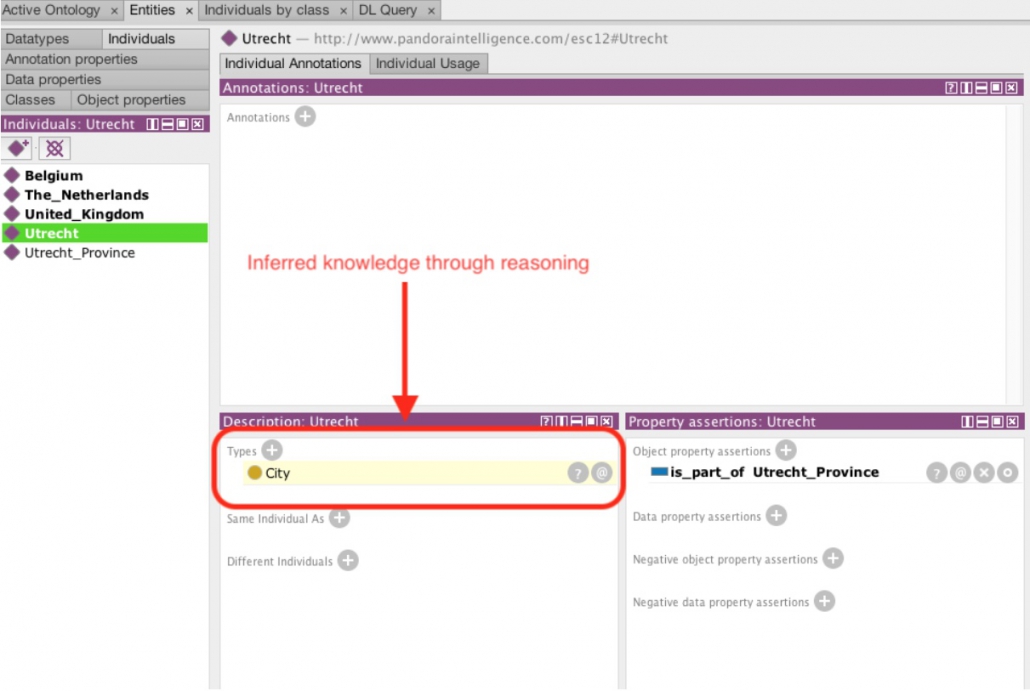
In the screenshot above you can see that the individual ‘Utrecht’ is an instance of the class ‘city’. This was inferred and you can find out how as well:
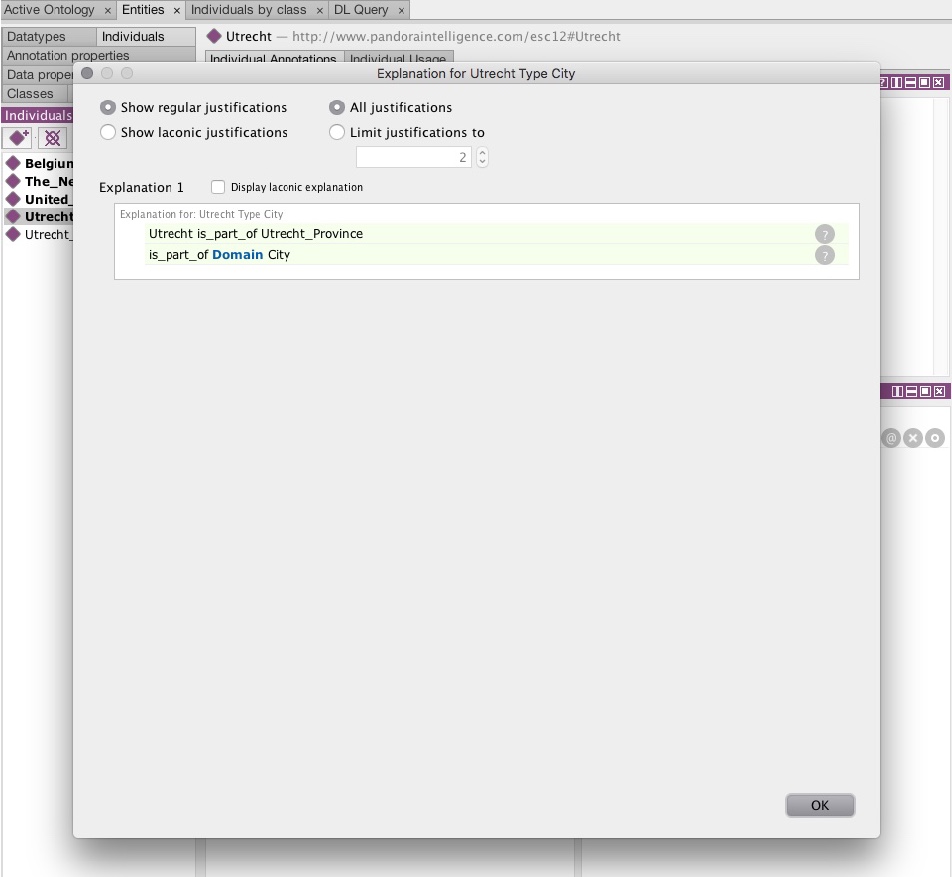
The reasoner tells you that since ‘Utrecht’ is part of ‘Utrecht Province’ and since ‘Utrecht Province’ has instances of ‘city’ the individual ‘Utrecht’ has to be an instance of ‘city’.
If you play a bit around with the tool and use other ontologies you can see that the justification for a deduction can originate from multiple paths:

These justifications effectively materialize the idea of provenance or traceability. The samples inside Protégé are very useful to see how things happen. Of course, a caution is in order: the inference is effectively a graph traversal under the hood and the bigger your data the more time consuming it is. This is where the standard stores deviate from the enterprise ones; if you pay some money for Stardog or AllegroGraph you will get better scalability.
On the other hand, maybe the default inference algorithms are not enough in your case and you need to invent custom rules. Systems like Fuseki are Java based and offer solid tools to articulate anything and everything.
Machine learning using semantic data
Inference is a way to create new data out of existing one. Machine learning is another way and some systems integrate both. Stardog, for example, has an easy to use API to create pedictive models out of triples. At this point you have to realize that semantic networks and typical ML algorithms clash a bit; frameworks like H2O, Spark, sklearn and whatnot all work on top of frames and data tables. As far as I know there is not ML algorithm working directly on semantic graphs, the all first extract-transform the data and only thereafter apply classic machine learning. The recipe in the case of Stardog is precisely that:
- you supply a SPARQL query to extract columnar data
- what is the target variable
- fit the data
once the model is created it becomes part of the data and can be used alongside other SPARQL queries.
For example, the following Stardog query will create a model
prefix spa:
SELECT * WHERE {
graph spa:model {
:myModel spa:arguments (?director ?year ?studio) ;
spa:predict ?predictedGenre .
}
:TheGodfather :directedBy ?director ;
:year ?year ;
:studio ?studio ;
:genre ?originalGenre .
}
where you need to note that spa:predict identifies the target variable and the second part identifies the tabular data. This creates a spa:mymodel which can used to predict new data:
prefix spa:
SELECT * WHERE {
graph spa:model {
:myModel spa:arguments (?director ?year ?studio) ;
spa:predict ?predictedGenre .
}
{
SELECT * WHERE {
?movie :directedBy ?director ;
:year ?year ;
:genre ?originalGenre .
OPTIONAL { ?movie :studio ?studio }
FILTER (?year > 2000)
}
}
}
All very simple but maybe still far away from advanced machine learning pipelines. What about wrangling data, cleaning it, optimising the model, validations and so on? The gap between semantic data and machine learning is narrowing in recent years, at this point it’s all very much ‘innovation’ rather than enterprise-ready.
Somewhat related to this, I should mention that there is also a momentum towards using semantic networks as neural networks, see e.g. the article Modeling Relational Data with Graph Convolutional Networks.
Objects, entities and structures
The relational data world is inexorably connected with ORM’s and frameworks to store/access/create (business) entities. The so-called data plumbing and CRUD of entities used to be indeed a software industry on its own (say, Hibernate and such). These frameworks are based on fixed schema and foreign-keys which allows one to create appropriate methods to easily navigate around the data.
The situation is less clear when dealing with ontologies. No foreign keys. No tables. No fields. If you do wish to travel back and forth between traditional business entities and triples you are very much on your own.
In principle, one could create a generator which takes in an ontology and generates a strongly types set of classes reflecting the underlying ontology. In principle, the related SPARQL queries could also be generated from a given ontology. Alas, you will not find this:
- it’s not clear in a graph or triple context what ‘deletion’ means when you have cycles. How far do you cascade deletions?
- it’s not clear what the boundary is on a triple-level of an entity. Various triples can or cannot be part of a business entity. Also, by enforcing too much strict adherence to an ontology you detach from the flexibility triples offer.
- what to do with triples pointing to external sources? Semantic networks do not separate data sets like RDBMS separate databases.
Business entities only partially map to an underlying triple store. You will have, in general, triples which do not map to properties of business objects. This can be a good thing or not depending or your concrete needs and aims. You only have to be aware of the different paradigms and how they are (un)related.
Systems, libraries and tools
Below you can find some of the things I found worth looking at. The semantic stage is evolving rapidly and there are some signs that ‘semantic’ will be part of a hype in the near future.
Stores
Most semantic stores are Java driven and have their origin in governmental or academic research. The pharma and biochemical industry is far ahead in adopting semantics in contrast to finance or, say, retail. You can find a topic called ‘semantic marketing’ but not everything labeled ‘semantic’ refers to triples and ontologies. Even within the software domain you can find ‘triple stores’ overlapping with graph stores and having little to do with ontologies or supporting SPARQL.
Every semantic store will allow you store triples and run SPARQL 1.1 queries, the differentiators are:
- scalability: do you need millions, trillions… of triples?
- availability: clustering, failover, distributed storage and all that.
- inference: speed of inference and API to implement custom inference algorithms.
- machine learning: do you need integrated ML, transparent import/export of tabular data?
- security: security groups access to named graphs something you wish?
If you have the cash, you will not be disappointed by
but they also come with a learning curve and dedicating FTE’s to managing it all. This is comparable to using MySQL versus Oracle 18c.
If you want to explore semantics and ontologies, go for Apache Fuseki and you will go a long way.
If Fuseki as a Java thing is an issue because you want to customize things then you should have a look at BrightstarDB which offers both an open source storage solution and an ORM.
Libraries
Since Java articulates many semantic stores it will be no surprise Java client libraries are very mature as well. The RDF4j API from Ontotext is related to GraphDB server boasting ultra fast forward-chaining reasoning and lots of high-tech goodies. If your language is Java or Scala then this your choice.
If you prefer .Net and C# in particular you need to look no further than dotnetRDF which connects to AllegroGraph, Jena, Stardog and Virtuoso. An alternative is the BrightstarDB entity framework which also includes a LINQ implementation. The affinity to the BrightstarDB server is noticeable and beware for a lock-in.
The RDFLib for Python is similar to dotnetRDF and offers the same scope and depth.
Note that client libraries are geared towards triples and ontologies. If you are looking for a bridge between your business objects and a triple store you are pretty much on your own. It doesn’t mean it’s complicated, just that the two worlds are not naturally present in most libraries, only the BrighstarDB ORM has this feature.
If you wish to apply a million of other R packages on semantic data you can use the SPARQL R package. The integration with iGraph and machine learning inside RStudio is probably a good place to start combining ML, AI and semantics. Or to create visualizations of triple data.
Finally, there is also a JavaScript-NodeJS rdflib.js module which has limited SPARQL support but should be sufficient in most cases. Few people use the full breadth of SPARQL anyway.
Tools
- A hidden gem is YASGUI to query your store. In fact, it’s a hub to query many stores, including dbpedia, biomodel citeseer and many more. The UI is integrated in a lot of commercial products (like Stardog) but can be used on its own.
- The DBPedia ontology is good reference to learn from a real-world ontology.
- GraphPath is reminiscent of XPath and allows you to query RDF paths (in function of inference).
- If you need sample data, the billions of DBPedia triples and million of WordNet triples are all a click away.
- A comparison of large triple stores might help you decide what works best for you. AllegroGraph leading with more than a trillion (!) triples.
What about Neo4J?
Neo4j is probably the number one graph storage solution on the market right now and has its own ecosystem. They have their own query language Cypher geared towards graphs. As such, it’s not focused on triples although they try hard to convince that it can be used for semantic knowledge. One can in fact hijack Neo4j for ontologies and inference but the whole experience is a bit awkward; it does not feel natural. Much like Microsoft’s CosmosDB, the focus is on graphs and not on triples. The difference might sound pedantic but is crucial. You cannot use SPARQL with Neo4j (though there are noble efforts), ontologies, inferences and all that is not natural to Neo4j. By natural I mean I would not take it into production. The counter-examples on Github are proof of concepts, not enterprise level solutions.
Note that I do advice to use Neo4j if your needs are not ontological and purely graph-like. Cypher and Neo4j are sublime, if used in the right context.

