Graph Nets
Artificial intelligence has undergone a renaissance recently, making major progress in key domains such as vision, language, control, and decision-making. This has been due, in part, to cheap data and cheap compute resources, which have fit the natural strengths of deep learning. However, many defining characteristics of human intelligence, which developed under much different pressures, remain out of reach for current approaches. In particular, generalizing beyond one’s experiences–a hallmark of human intelligence from infancy–remains a formidable challenge for modern AI.
A combinatorial generalization must be a priority for AI to achieve human-like abilities, structured representations and computations are key to realizing this objective. Just as biology uses nature and nurture cooperatively, we reject the false choice between “hand-engineering” and “end-to-end” learning, and instead advocate for an approach which benefits from their complementary strengths. Graph nets explore how using relational inductive biases within deep learning architectures can facilitate learning about entities, relations, and rules for composing them. Graph nets is an AI toolkit with a strong relational inductive bias–the graph network–which generalizes and extends various approaches for neural networks that operate on graphs, and provides a straightforward interface for manipulating structured knowledge and producing structured behaviors. Networks can support relational reasoning and combinatorial generalization, laying the foundation for more sophisticated, interpretable, and flexible patterns of reasoning.
First, install the package:
pip install graph_nets
and import it
from __future__ import absolute_import from __future__ import division from __future__ import print_function import collections import itertools import time from graph_nets import graphs from graph_nets import utils_np from graph_nets import utils_tf from graph_nets.demos import models import matplotlib.pyplot as plt import networkx as nx import numpy as np from scipy import spatial import tensorflow as tf SEED = 1 np.random.seed(SEED) tf.set_random_seed(SEED)
Graphs have to be generated and much like a tabular learning pipeline you need some utilities to streamline it all:
DISTANCE_WEIGHT_NAME = "distance" # The name for the distance edge attribute.
def pairwise(iterable):
"""s -> (s0,s1), (s1,s2), (s2, s3), ..."""
a, b = itertools.tee(iterable)
next(b, None)
return zip(a, b)
def set_diff(seq0, seq1):
"""Return the set difference between 2 sequences as a list."""
return list(set(seq0) - set(seq1))
def to_one_hot(indices, max_value, axis=-1):
one_hot = np.eye(max_value)[indices]
if axis not in (-1, one_hot.ndim):
one_hot = np.moveaxis(one_hot, -1, axis)
return one_hot
def get_node_dict(graph, attr):
"""Return a `dict` of node:attribute pairs from a graph."""
return {k: v[attr] for k, v in graph.node.items()}
def generate_graph(rand,
num_nodes_min_max,
dimensions=2,
theta=1000.0,
rate=1.0):
"""Creates a connected graph.
The graphs are geographic threshold graphs, but with added edges via a
minimum spanning tree algorithm, to ensure all nodes are connected.
Args:
rand: A random seed for the graph generator. Default= None.
num_nodes_min_max: A sequence [lower, upper) number of nodes per graph.
dimensions: (optional) An `int` number of dimensions for the positions.
Default= 2.
theta: (optional) A `float` threshold parameters for the geographic
threshold graph's threshold. Large values (1000+) make mostly trees. Try
20-60 for good non-trees. Default=1000.0.
rate: (optional) A rate parameter for the node weight exponential sampling
distribution. Default= 1.0.
Returns:
The graph.
"""
# Sample num_nodes.
num_nodes = rand.randint(*num_nodes_min_max)
# Create geographic threshold graph.
pos_array = rand.uniform(size=(num_nodes, dimensions))
pos = dict(enumerate(pos_array))
weight = dict(enumerate(rand.exponential(rate, size=num_nodes)))
geo_graph = nx.geographical_threshold_graph(
num_nodes, theta, pos=pos, weight=weight)
# Create minimum spanning tree across geo_graph's nodes.
distances = spatial.distance.squareform(spatial.distance.pdist(pos_array))
i_, j_ = np.meshgrid(range(num_nodes), range(num_nodes), indexing="ij")
weighted_edges = list(zip(i_.ravel(), j_.ravel(), distances.ravel()))
mst_graph = nx.Graph()
mst_graph.add_weighted_edges_from(weighted_edges, weight=DISTANCE_WEIGHT_NAME)
mst_graph = nx.minimum_spanning_tree(mst_graph, weight=DISTANCE_WEIGHT_NAME)
# Put geo_graph's node attributes into the mst_graph.
for i in mst_graph.nodes():
mst_graph.node[i].update(geo_graph.node[i])
# Compose the graphs.
combined_graph = nx.compose_all((mst_graph, geo_graph.copy()))
# Put all distance weights into edge attributes.
for i, j in combined_graph.edges():
combined_graph.get_edge_data(i, j).setdefault(DISTANCE_WEIGHT_NAME,
distances[i, j])
return combined_graph, mst_graph, geo_graph
def add_shortest_path(rand, graph, min_length=1):
"""Samples a shortest path from A to B and adds attributes to indicate it.
Args:
rand: A random seed for the graph generator. Default= None.
graph: A `nx.Graph`.
min_length: (optional) An `int` minimum number of edges in the shortest
path. Default= 1.
Returns:
The `nx.DiGraph` with the shortest path added.
Raises:
ValueError: All shortest paths are below the minimum length
"""
# Map from node pairs to the length of their shortest path.
pair_to_length_dict = {}
try:
# This is for compatibility with older networkx.
lengths = nx.all_pairs_shortest_path_length(graph).items()
except AttributeError:
# This is for compatibility with newer networkx.
lengths = list(nx.all_pairs_shortest_path_length(graph))
for x, yy in lengths:
for y, l in yy.items():
if l >= min_length:
pair_to_length_dict[x, y] = l
if max(pair_to_length_dict.values()) < min_length:
raise ValueError("All shortest paths are below the minimum length")
# The node pairs which exceed the minimum length.
node_pairs = list(pair_to_length_dict)
# Computes probabilities per pair, to enforce uniform sampling of each
# shortest path lengths.
# The counts of pairs per length.
counts = collections.Counter(pair_to_length_dict.values())
prob_per_length = 1.0 / len(counts)
probabilities = [
prob_per_length / counts[pair_to_length_dict[x]] for x in node_pairs
]
# Choose the start and end points.
i = rand.choice(len(node_pairs), p=probabilities)
start, end = node_pairs[i]
path = nx.shortest_path(
graph, source=start, target=end, weight=DISTANCE_WEIGHT_NAME)
# Creates a directed graph, to store the directed path from start to end.
digraph = graph.to_directed()
# Add the "start", "end", and "solution" attributes to the nodes and edges.
digraph.add_node(start, start=True)
digraph.add_node(end, end=True)
digraph.add_nodes_from(set_diff(digraph.nodes(), [start]), start=False)
digraph.add_nodes_from(set_diff(digraph.nodes(), [end]), end=False)
digraph.add_nodes_from(set_diff(digraph.nodes(), path), solution=False)
digraph.add_nodes_from(path, solution=True)
path_edges = list(pairwise(path))
digraph.add_edges_from(set_diff(digraph.edges(), path_edges), solution=False)
digraph.add_edges_from(path_edges, solution=True)
return digraph
def graph_to_input_target(graph):
"""Returns 2 graphs with input and target feature vectors for training.
Args:
graph: An `nx.DiGraph` instance.
Returns:
The input `nx.DiGraph` instance.
The target `nx.DiGraph` instance.
Raises:
ValueError: unknown node type
"""
def create_feature(attr, fields):
return np.hstack([np.array(attr[field], dtype=float) for field in fields])
input_node_fields = ("pos", "weight", "start", "end")
input_edge_fields = ("distance",)
target_node_fields = ("solution",)
target_edge_fields = ("solution",)
input_graph = graph.copy()
target_graph = graph.copy()
solution_length = 0
for node_index, node_feature in graph.nodes(data=True):
input_graph.add_node(
node_index, features=create_feature(node_feature, input_node_fields))
target_node = to_one_hot(
create_feature(node_feature, target_node_fields).astype(int), 2)[0]
target_graph.add_node(node_index, features=target_node)
solution_length += int(node_feature["solution"])
solution_length /= graph.number_of_nodes()
for receiver, sender, features in graph.edges(data=True):
input_graph.add_edge(
sender, receiver, features=create_feature(features, input_edge_fields))
target_edge = to_one_hot(
create_feature(features, target_edge_fields).astype(int), 2)[0]
target_graph.add_edge(sender, receiver, features=target_edge)
input_graph.graph["features"] = np.array([0.0])
target_graph.graph["features"] = np.array([solution_length], dtype=float)
return input_graph, target_graph
def generate_networkx_graphs(rand, num_examples, num_nodes_min_max, theta):
"""Generate graphs for training.
Args:
rand: A random seed (np.RandomState instance).
num_examples: Total number of graphs to generate.
num_nodes_min_max: A 2-tuple with the [lower, upper) number of nodes per
graph. The number of nodes for a graph is uniformly sampled within this
range.
theta: (optional) A `float` threshold parameters for the geographic
threshold graph's threshold. Default= the number of nodes.
Returns:
input_graphs: The list of input graphs.
target_graphs: The list of output graphs.
graphs: The list of generated graphs.
"""
input_graphs = []
target_graphs = []
graphs = []
for _ in range(num_examples):
graph = generate_graph(rand, num_nodes_min_max, theta=theta)[0]
graph = add_shortest_path(rand, graph)
input_graph, target_graph = graph_to_input_target(graph)
input_graphs.append(input_graph)
target_graphs.append(target_graph)
graphs.append(graph)
return input_graphs, target_graphs, graphs
def create_placeholders(rand, batch_size, num_nodes_min_max, theta):
"""Creates placeholders for the model training and evaluation.
Args:
rand: A random seed (np.RandomState instance).
batch_size: Total number of graphs per batch.
num_nodes_min_max: A 2-tuple with the [lower, upper) number of nodes per
graph. The number of nodes for a graph is uniformly sampled within this
range.
theta: A `float` threshold parameters for the geographic threshold graph's
threshold. Default= the number of nodes.
Returns:
input_ph: The input graph's placeholders, as a graph namedtuple.
target_ph: The target graph's placeholders, as a graph namedtuple.
"""
# Create some example data for inspecting the vector sizes.
input_graphs, target_graphs, _ = generate_networkx_graphs(
rand, batch_size, num_nodes_min_max, theta)
input_ph = utils_tf.placeholders_from_networkxs(
input_graphs, force_dynamic_num_graphs=True)
target_ph = utils_tf.placeholders_from_networkxs(
target_graphs, force_dynamic_num_graphs=True)
return input_ph, target_ph
def create_feed_dict(rand, batch_size, num_nodes_min_max, theta, input_ph,
target_ph):
"""Creates placeholders for the model training and evaluation.
Args:
rand: A random seed (np.RandomState instance).
batch_size: Total number of graphs per batch.
num_nodes_min_max: A 2-tuple with the [lower, upper) number of nodes per
graph. The number of nodes for a graph is uniformly sampled within this
range.
theta: A `float` threshold parameters for the geographic threshold graph's
threshold. Default= the number of nodes.
input_ph: The input graph's placeholders, as a graph namedtuple.
target_ph: The target graph's placeholders, as a graph namedtuple.
Returns:
feed_dict: The feed `dict` of input and target placeholders and data.
raw_graphs: The `dict` of raw networkx graphs.
"""
inputs, targets, raw_graphs = generate_networkx_graphs(
rand, batch_size, num_nodes_min_max, theta)
input_graphs = utils_np.networkxs_to_graphs_tuple(inputs)
target_graphs = utils_np.networkxs_to_graphs_tuple(targets)
feed_dict = {input_ph: input_graphs, target_ph: target_graphs}
return feed_dict, raw_graphs
def compute_accuracy(target, output, use_nodes=True, use_edges=False):
"""Calculate model accuracy.
Returns the number of correctly predicted shortest path nodes and the number
of completely solved graphs (100% correct predictions).
Args:
target: A `graphs.GraphsTuple` that contains the target graph.
output: A `graphs.GraphsTuple` that contains the output graph.
use_nodes: A `bool` indicator of whether to compute node accuracy or not.
use_edges: A `bool` indicator of whether to compute edge accuracy or not.
Returns:
correct: A `float` fraction of correctly labeled nodes/edges.
solved: A `float` fraction of graphs that are completely correctly labeled.
Raises:
ValueError: Nodes or edges (or both) must be used
"""
if not use_nodes and not use_edges:
raise ValueError("Nodes or edges (or both) must be used")
tdds = utils_np.graphs_tuple_to_data_dicts(target)
odds = utils_np.graphs_tuple_to_data_dicts(output)
cs = []
ss = []
for td, od in zip(tdds, odds):
xn = np.argmax(td["nodes"], axis=-1)
yn = np.argmax(od["nodes"], axis=-1)
xe = np.argmax(td["edges"], axis=-1)
ye = np.argmax(od["edges"], axis=-1)
c = []
if use_nodes:
c.append(xn == yn)
if use_edges:
c.append(xe == ye)
c = np.concatenate(c, axis=0)
s = np.all(c)
cs.append(c)
ss.append(s)
correct = np.mean(np.concatenate(cs, axis=0))
solved = np.mean(np.stack(ss))
return correct, solved
def create_loss_ops(target_op, output_ops):
loss_ops = [
tf.losses.softmax_cross_entropy(target_op.nodes, output_op.nodes) +
tf.losses.softmax_cross_entropy(target_op.edges, output_op.edges)
for output_op in output_ops
]
return loss_ops
def make_all_runnable_in_session(*args):
"""Lets an iterable of TF graphs be output from a session as NP graphs."""
return [utils_tf.make_runnable_in_session(a) for a in args]
class GraphPlotter(object):
def __init__(self, ax, graph, pos):
self._ax = ax
self._graph = graph
self._pos = pos
self._base_draw_kwargs = dict(G=self._graph, pos=self._pos, ax=self._ax)
self._solution_length = None
self._nodes = None
self._edges = None
self._start_nodes = None
self._end_nodes = None
self._solution_nodes = None
self._intermediate_solution_nodes = None
self._solution_edges = None
self._non_solution_nodes = None
self._non_solution_edges = None
self._ax.set_axis_off()
@property
def solution_length(self):
if self._solution_length is None:
self._solution_length = len(self._solution_edges)
return self._solution_length
@property
def nodes(self):
if self._nodes is None:
self._nodes = self._graph.nodes()
return self._nodes
@property
def edges(self):
if self._edges is None:
self._edges = self._graph.edges()
return self._edges
@property
def start_nodes(self):
if self._start_nodes is None:
self._start_nodes = [
n for n in self.nodes if self._graph.node[n].get("start", False)
]
return self._start_nodes
@property
def end_nodes(self):
if self._end_nodes is None:
self._end_nodes = [
n for n in self.nodes if self._graph.node[n].get("end", False)
]
return self._end_nodes
@property
def solution_nodes(self):
if self._solution_nodes is None:
self._solution_nodes = [
n for n in self.nodes if self._graph.node[n].get("solution", False)
]
return self._solution_nodes
@property
def intermediate_solution_nodes(self):
if self._intermediate_solution_nodes is None:
self._intermediate_solution_nodes = [
n for n in self.nodes
if self._graph.node[n].get("solution", False) and
not self._graph.node[n].get("start", False) and
not self._graph.node[n].get("end", False)
]
return self._intermediate_solution_nodes
@property
def solution_edges(self):
if self._solution_edges is None:
self._solution_edges = [
e for e in self.edges
if self._graph.get_edge_data(e[0], e[1]).get("solution", False)
]
return self._solution_edges
@property
def non_solution_nodes(self):
if self._non_solution_nodes is None:
self._non_solution_nodes = [
n for n in self.nodes
if not self._graph.node[n].get("solution", False)
]
return self._non_solution_nodes
@property
def non_solution_edges(self):
if self._non_solution_edges is None:
self._non_solution_edges = [
e for e in self.edges
if not self._graph.get_edge_data(e[0], e[1]).get("solution", False)
]
return self._non_solution_edges
def _make_draw_kwargs(self, **kwargs):
kwargs.update(self._base_draw_kwargs)
return kwargs
def _draw(self, draw_function, zorder=None, **kwargs):
draw_kwargs = self._make_draw_kwargs(**kwargs)
collection = draw_function(**draw_kwargs)
if collection is not None and zorder is not None:
try:
# This is for compatibility with older matplotlib.
collection.set_zorder(zorder)
except AttributeError:
# This is for compatibility with newer matplotlib.
collection[0].set_zorder(zorder)
return collection
def draw_nodes(self, **kwargs):
"""Useful kwargs: nodelist, node_size, node_color, linewidths."""
if ("node_color" in kwargs and
isinstance(kwargs["node_color"], collections.Sequence) and
len(kwargs["node_color"]) in {3, 4} and
not isinstance(kwargs["node_color"][0],
(collections.Sequence, np.ndarray))):
num_nodes = len(kwargs.get("nodelist", self.nodes))
kwargs["node_color"] = np.tile(
np.array(kwargs["node_color"])[None], [num_nodes, 1])
return self._draw(nx.draw_networkx_nodes, **kwargs)
def draw_edges(self, **kwargs):
"""Useful kwargs: edgelist, width."""
return self._draw(nx.draw_networkx_edges, **kwargs)
def draw_graph(self,
node_size=200,
node_color=(0.4, 0.8, 0.4),
node_linewidth=1.0,
edge_width=1.0):
# Plot nodes.
self.draw_nodes(
nodelist=self.nodes,
node_size=node_size,
node_color=node_color,
linewidths=node_linewidth,
zorder=20)
# Plot edges.
self.draw_edges(edgelist=self.edges, width=edge_width, zorder=10)
def draw_graph_with_solution(self,
node_size=200,
node_color=(0.4, 0.8, 0.4),
node_linewidth=1.0,
edge_width=1.0,
start_color="w",
end_color="k",
solution_node_linewidth=3.0,
solution_edge_width=3.0):
node_border_color = (0.0, 0.0, 0.0, 1.0)
node_collections = {}
# Plot start nodes.
node_collections["start nodes"] = self.draw_nodes(
nodelist=self.start_nodes,
node_size=node_size,
node_color=start_color,
linewidths=solution_node_linewidth,
edgecolors=node_border_color,
zorder=100)
# Plot end nodes.
node_collections["end nodes"] = self.draw_nodes(
nodelist=self.end_nodes,
node_size=node_size,
node_color=end_color,
linewidths=solution_node_linewidth,
edgecolors=node_border_color,
zorder=90)
# Plot intermediate solution nodes.
if isinstance(node_color, dict):
c = [node_color[n] for n in self.intermediate_solution_nodes]
else:
c = node_color
node_collections["intermediate solution nodes"] = self.draw_nodes(
nodelist=self.intermediate_solution_nodes,
node_size=node_size,
node_color=c,
linewidths=solution_node_linewidth,
edgecolors=node_border_color,
zorder=80)
# Plot solution edges.
node_collections["solution edges"] = self.draw_edges(
edgelist=self.solution_edges, width=solution_edge_width, zorder=70)
# Plot non-solution nodes.
if isinstance(node_color, dict):
c = [node_color[n] for n in self.non_solution_nodes]
else:
c = node_color
node_collections["non-solution nodes"] = self.draw_nodes(
nodelist=self.non_solution_nodes,
node_size=node_size,
node_color=c,
linewidths=node_linewidth,
edgecolors=node_border_color,
zorder=20)
# Plot non-solution edges.
node_collections["non-solution edges"] = self.draw_edges(
edgelist=self.non_solution_edges, width=edge_width, zorder=10)
# Set title as solution length.
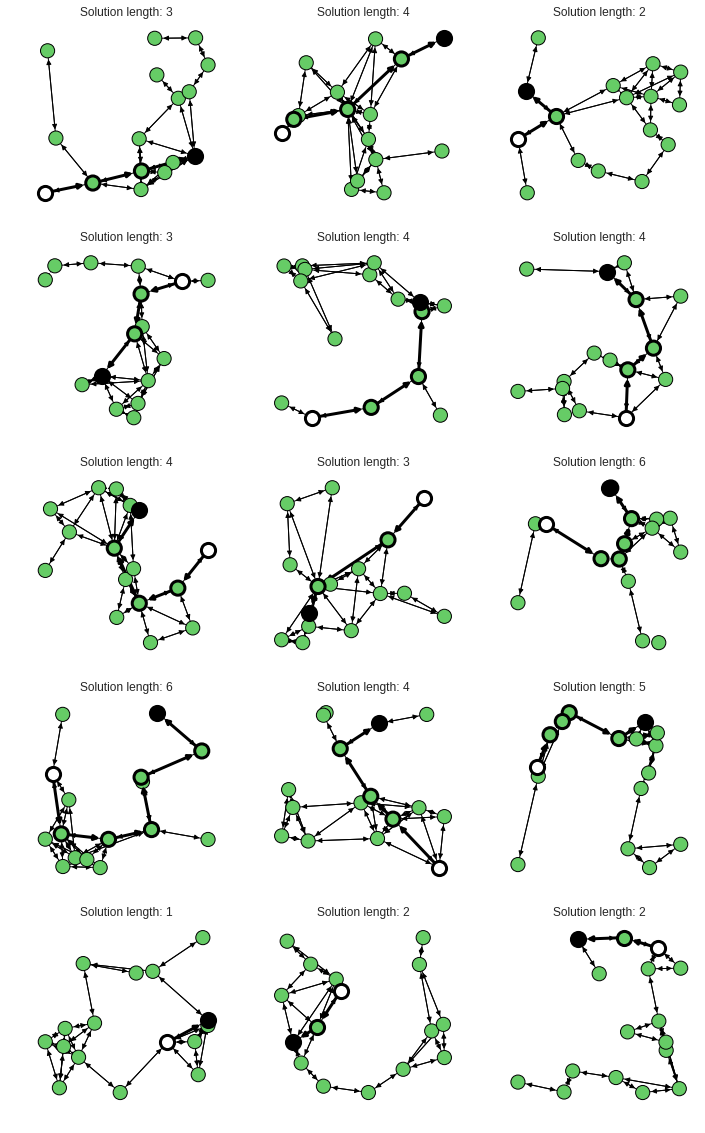
self._ax.set_title("Solution length: {}".format(self.solution_length))
return node_collections
With this one can output some nice graphs:
seed = 165 #@param{type: 'integer'}
rand = np.random.RandomState(seed=seed)
num_examples = 15 #@param{type: 'integer'}
# Large values (1000+) make trees. Try 20-60 for good non-trees.
theta = 20 #@param{type: 'integer'}
num_nodes_min_max = (16, 17)
input_graphs, target_graphs, graphs = generate_networkx_graphs(
rand, num_examples, num_nodes_min_max, theta)
num = min(num_examples, 16)
w = 3
h = int(np.ceil(num / w))
fig = plt.figure(40, figsize=(w * 4, h * 4))
fig.clf()
for j, graph in enumerate(graphs):
ax = fig.add_subplot(h, w, j + 1)
pos = get_node_dict(graph, "pos")
plotter = GraphPlotter(ax, graph, pos)
plotter.draw_graph_with_solution()
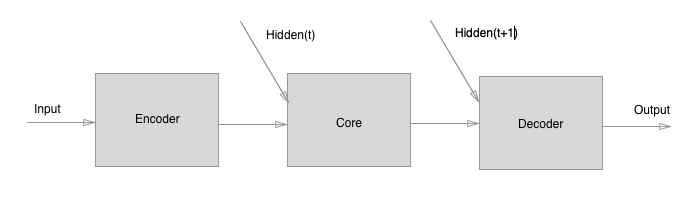
The model we explore includes three components:
- An "Encoder" graph net, which independently encodes the edge, node, and
global attributes (does not compute relations etc.).
- A "Core" graph net, which performs N rounds of processing (message-passing)
steps. The input to the Core is the concatenation of the Encoder's output
and the previous output of the Core (labeled "Hidden(t)" below, where "t" is
the processing step).
- A "Decoder" graph net, which independently decodes the edge, node, and
global attributes (does not compute relations etc.), on each
message-passing step.
The model is trained by supervised learning. Input graphs are procedurally
generated, and output graphs have the same structure with the nodes and edges
of the shortest path labeled (using 2-element 1-hot vectors). We could have
predicted the shortest path only by labeling either the nodes or edges, and
that does work, but we decided to predict both to demonstrate the flexibility
of graph nets' outputs.
The training loss is computed on the output of each processing step. The
reason for this is to encourage the model to try to solve the problem in as
few steps as possible. It also helps make the output of intermediate steps
more interpretable.
There's no need for a separate evaluate dataset because the inputs are
never repeated, so the training loss is the measure of performance on graphs
from the input distribution.
We also evaluate how well the models generalize to graphs which are up to
twice as large as those on which it was trained. The loss is computed only
on the final processing step.
Variables with the suffix _tr are training parameters, and variables with the
suffix _ge are test/generalization parameters.
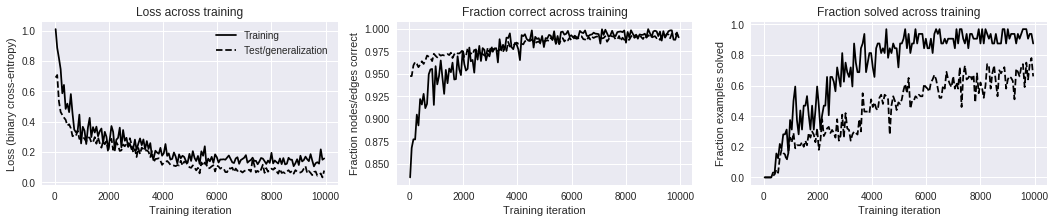
After around 2000-5000 training iterations the model reaches near-perfect
performance on graphs with between 8-16 nodes.
tf.reset_default_graph()
seed = 2
rand = np.random.RandomState(seed=seed)
# Model parameters.
# Number of processing (message-passing) steps.
num_processing_steps_tr = 10
num_processing_steps_ge = 10
# Data / training parameters.
num_training_iterations = 10000
theta = 20 # Large values (1000+) make trees. Try 20-60 for good non-trees.
batch_size_tr = 32
batch_size_ge = 100
# Number of nodes per graph sampled uniformly from this range.
num_nodes_min_max_tr = (8, 17)
num_nodes_min_max_ge = (16, 33)
# Data.
# Input and target placeholders.
input_ph, target_ph = create_placeholders(rand, batch_size_tr,
num_nodes_min_max_tr, theta)
# Connect the data to the model.
# Instantiate the model.
model = models.EncodeProcessDecode(edge_output_size=2, node_output_size=2)
# A list of outputs, one per processing step.
output_ops_tr = model(input_ph, num_processing_steps_tr)
output_ops_ge = model(input_ph, num_processing_steps_ge)
# Training loss.
loss_ops_tr = create_loss_ops(target_ph, output_ops_tr)
# Loss across processing steps.
loss_op_tr = sum(loss_ops_tr) / num_processing_steps_tr
# Test/generalization loss.
loss_ops_ge = create_loss_ops(target_ph, output_ops_ge)
loss_op_ge = loss_ops_ge[-1] # Loss from final processing step.
# Optimizer.
learning_rate = 1e-3
optimizer = tf.train.AdamOptimizer(learning_rate)
step_op = optimizer.minimize(loss_op_tr)
# Lets an iterable of TF graphs be output from a session as NP graphs.
input_ph, target_ph = make_all_runnable_in_session(input_ph, target_ph)
This cell resets the Tensorflow session, but keeps the same computational graph.
try: sess.close() except NameError: pass sess = tf.Session() sess.run(tf.global_variables_initializer()) last_iteration = 0 logged_iterations = [] losses_tr = [] corrects_tr = [] solveds_tr = [] losses_ge = [] corrects_ge = [] solveds_ge = []
You can interrupt this cell's training loop at any time, and visualize the intermediate results by running the next cell (below). You can then resume training by simply executing this cell again.
# How much time between logging and printing the current results.
log_every_seconds = 20
print("# (iteration number), T (elapsed seconds), "
"Ltr (training loss), Lge (test/generalization loss), "
"Ctr (training fraction nodes/edges labeled correctly), "
"Str (training fraction examples solved correctly), "
"Cge (test/generalization fraction nodes/edges labeled correctly), "
"Sge (test/generalization fraction examples solved correctly)")
start_time = time.time()
last_log_time = start_time
for iteration in range(last_iteration, num_training_iterations):
last_iteration = iteration
feed_dict, _ = create_feed_dict(rand, batch_size_tr, num_nodes_min_max_tr,
theta, input_ph, target_ph)
train_values = sess.run({
"step": step_op,
"target": target_ph,
"loss": loss_op_tr,
"outputs": output_ops_tr
},
feed_dict=feed_dict)
the_time = time.time()
elapsed_since_last_log = the_time - last_log_time
if elapsed_since_last_log > log_every_seconds:
last_log_time = the_time
feed_dict, raw_graphs = create_feed_dict(
rand, batch_size_ge, num_nodes_min_max_ge, theta, input_ph, target_ph)
test_values = sess.run({
"target": target_ph,
"loss": loss_op_ge,
"outputs": output_ops_ge
},
feed_dict=feed_dict)
correct_tr, solved_tr = compute_accuracy(
train_values["target"], train_values["outputs"][-1], use_edges=True)
correct_ge, solved_ge = compute_accuracy(
test_values["target"], test_values["outputs"][-1], use_edges=True)
elapsed = time.time() - start_time
losses_tr.append(train_values["loss"])
corrects_tr.append(correct_tr)
solveds_tr.append(solved_tr)
losses_ge.append(test_values["loss"])
corrects_ge.append(correct_ge)
solveds_ge.append(solved_ge)
logged_iterations.append(iteration)
print("# {:05d}, T {:.1f}, Ltr {:.4f}, Lge {:.4f}, Ctr {:.4f}, Str"
" {:.4f}, Cge {:.4f}, Sge {:.4f}".format(
iteration, elapsed, train_values["loss"], test_values["loss"],
correct_tr, solved_tr, correct_ge, solved_ge))
# (iteration number), T (elapsed seconds), Ltr (training loss), Lge (test/generalization loss), Ctr (training fraction nodes/edges labeled correctly), Str (training fraction examples solved correctly), Cge (test/generalization fraction nodes/edges labeled correctly), Sge (test/generalization fraction examples solved correctly)
# 00038, T 22.9, Ltr 1.0097, Lge 0.6905, Ctr 0.8351, Str 0.0000, Cge 0.9474, Sge 0.0000
# 00096, T 41.9, Ltr 0.8867, Lge 0.7074, Ctr 0.8678, Str 0.0000, Cge 0.9474, Sge 0.0000
# 00160, T 61.9, Ltr 0.8190, Lge 0.5330, Ctr 0.8773, Str 0.0000, Cge 0.9592, Sge 0.0000
# 00223, T 81.9, Ltr 0.7457, Lge 0.4636, Ctr 0.8772, Str 0.0000, Cge 0.9629, Sge 0.0000
# 00285, T 102.2, Ltr 0.5869, Lge 0.4440, Ctr 0.9047, Str 0.0000, Cge 0.9609, Sge 0.0000
# 00345, T 122.4, Ltr 0.6421, Lge 0.4271, Ctr 0.8927, Str 0.0312, Cge 0.9572, Sge 0.0100
# 00408, T 142.4, Ltr 0.4840, Lge 0.4120, Ctr 0.9219, Str 0.0312, Cge 0.9602, Sge 0.0200
# 00471, T 162.7, Ltr 0.5184, Lge 0.3747, Ctr 0.9159, Str 0.1562, Cge 0.9638, Sge 0.0500
# 00536, T 182.9, Ltr 0.4626, Lge 0.3830, Ctr 0.9277, Str 0.1250, Cge 0.9609, Sge 0.0300
# 00599, T 203.0, Ltr 0.5819, Lge 0.3564, Ctr 0.9119, Str 0.2188, Cge 0.9645, Sge 0.1300
# 00662, T 223.3, Ltr 0.4533, Lge 0.3038, Ctr 0.9166, Str 0.1875, Cge 0.9701, Sge 0.1800
...
# 09884, T 3184.2, Ltr 0.1494, Lge 0.0328, Ctr 0.9943, Str 0.9375, Cge 0.9956, Sge 0.7800
# 09948, T 3204.5, Ltr 0.1576, Lge 0.0778, Ctr 0.9903, Str 0.8750, Cge 0.9892, Sge 0.6600
This cell visualizes the results of training. You can visualize the intermediate results by interrupting execution of the cell above, and running this cell. You can then resume training by simply executing the above cell again.
def softmax_prob_last_dim(x): # pylint: disable=redefined-outer-name
e = np.exp(x)
return e[:, -1] / np.sum(e, axis=-1)
# Plot results curves.
fig = plt.figure(1, figsize=(18, 3))
fig.clf()
x = np.array(logged_iterations)
# Loss.
y_tr = losses_tr
y_ge = losses_ge
ax = fig.add_subplot(1, 3, 1)
ax.plot(x, y_tr, "k", label="Training")
ax.plot(x, y_ge, "k--", label="Test/generalization")
ax.set_title("Loss across training")
ax.set_xlabel("Training iteration")
ax.set_ylabel("Loss (binary cross-entropy)")
ax.legend()
# Correct.
y_tr = corrects_tr
y_ge = corrects_ge
ax = fig.add_subplot(1, 3, 2)
ax.plot(x, y_tr, "k", label="Training")
ax.plot(x, y_ge, "k--", label="Test/generalization")
ax.set_title("Fraction correct across training")
ax.set_xlabel("Training iteration")
ax.set_ylabel("Fraction nodes/edges correct")
# Solved.
y_tr = solveds_tr
y_ge = solveds_ge
ax = fig.add_subplot(1, 3, 3)
ax.plot(x, y_tr, "k", label="Training")
ax.plot(x, y_ge, "k--", label="Test/generalization")
ax.set_title("Fraction solved across training")
ax.set_xlabel("Training iteration")
ax.set_ylabel("Fraction examples solved")
# Plot graphs and results after each processing step.
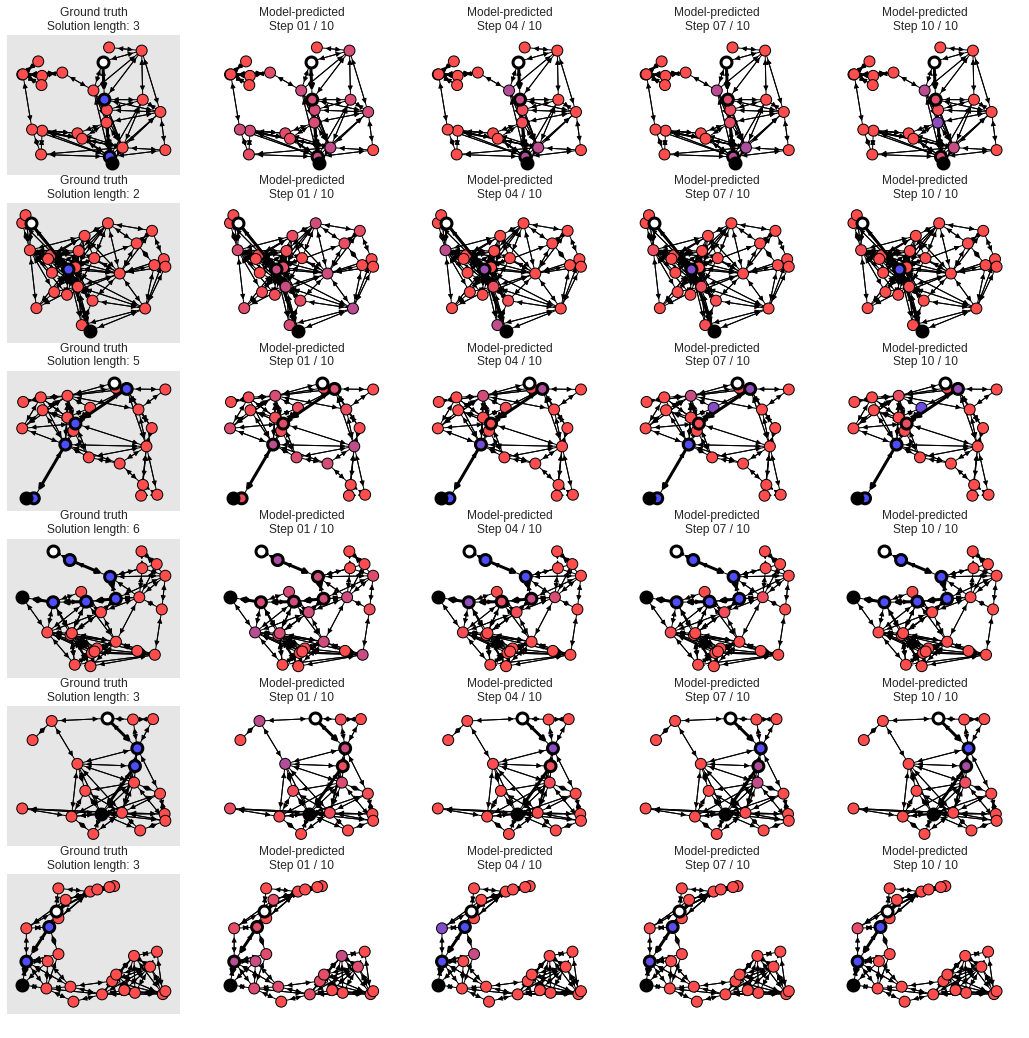
# The white node is the start, and the black is the end. Other nodes are colored
# from red to purple to blue, where red means the model is confident the node is
# off the shortest path, blue means the model is confident the node is on the
# shortest path, and purplish colors mean the model isn't sure.
max_graphs_to_plot = 6
num_steps_to_plot = 4
node_size = 120
min_c = 0.3
num_graphs = len(raw_graphs)
targets = utils_np.graphs_tuple_to_data_dicts(test_values["target"])
step_indices = np.floor(
np.linspace(0, num_processing_steps_ge - 1,
num_steps_to_plot)).astype(int).tolist()
outputs = list(
zip(*(utils_np.graphs_tuple_to_data_dicts(test_values["outputs"][i])
for i in step_indices)))
h = min(num_graphs, max_graphs_to_plot)
w = num_steps_to_plot + 1
fig = plt.figure(101, figsize=(18, h * 3))
fig.clf()
ncs = []
for j, (graph, target, output) in enumerate(zip(raw_graphs, targets, outputs)):
if j >= h:
break
pos = get_node_dict(graph, "pos")
ground_truth = target["nodes"][:, -1]
# Ground truth.
iax = j * (1 + num_steps_to_plot) + 1
ax = fig.add_subplot(h, w, iax)
plotter = GraphPlotter(ax, graph, pos)
color = {}
for i, n in enumerate(plotter.nodes):
color[n] = np.array([1.0 - ground_truth[i], 0.0, ground_truth[i], 1.0
]) * (1.0 - min_c) + min_c
plotter.draw_graph_with_solution(node_size=node_size, node_color=color)
ax.set_axis_on()
ax.set_xticks([])
ax.set_yticks([])
try:
ax.set_facecolor([0.9] * 3 + [1.0])
except AttributeError:
ax.set_axis_bgcolor([0.9] * 3 + [1.0])
ax.grid(None)
ax.set_title("Ground truth\nSolution length: {}".format(
plotter.solution_length))
# Prediction.
for k, outp in enumerate(output):
iax = j * (1 + num_steps_to_plot) + 2 + k
ax = fig.add_subplot(h, w, iax)
plotter = GraphPlotter(ax, graph, pos)
color = {}
prob = softmax_prob_last_dim(outp["nodes"])
for i, n in enumerate(plotter.nodes):
color[n] = np.array([1.0 - prob[n], 0.0, prob[n], 1.0
]) * (1.0 - min_c) + min_c
plotter.draw_graph_with_solution(node_size=node_size, node_color=color)
ax.set_title("Model-predicted\nStep {:02d} / {:02d}".format(
step_indices[k] + 1, step_indices[-1] + 1))